1 引言
各位朋友大家好,欢迎来到月来客栈。在前面的几篇文章中,笔者陆续介绍了多头注意力机制的原理、Transformer中编码器和解码器的工作流程以及多头注意力的实现过程等。在这篇文章中,笔者将会一步一步地来详细介绍如何通过Pytorch框架实现Transformer的整体网络结构,包括Token Embedding、Positional Embedding、编码器和解码器等。
下面,首先要介绍的就是对于Embedding部分的编码实现。
2 Embedding 实现
2.1 Token Embedding
这里首先要实现的便是最基础的Token Enbedding,也是字符转向量的一种常用做法,如下所示:
x1class TokenEmbedding(nn.Module):2 def __init__(self, vocab_size: int, emb_size):3 super(TokenEmbedding, self).__init__()4 self.embedding = nn.Embedding(vocab_size, emb_size)5 self.emb_size = emb_size67 def forward(self, tokens):8 """9 :param tokens: shape : [len, batch_size] 10 :return: shape: [len, batch_size, emb_size]11 """12 return self.embedding(tokens.long()) * math.sqrt(self.emb_size)如上代码所示便是TokenEmbedding的实现过程,由于这部分代码并不复杂所以就不再逐行进行介绍。注意,第12行代码对原始向量进行缩放是出自论文中3.4部分的描述。
2.2 Positional Embedding
在前一篇文章中笔者已经对Positional Embedding的原理做了详细的介绍,其每个位置的变化方式如式所示。
进一步,我们还可以对式中括号内的参数进行化简得到如式中的形式。
由此,根据式便可以实现Positional Embedding部分的代码,如下所示:
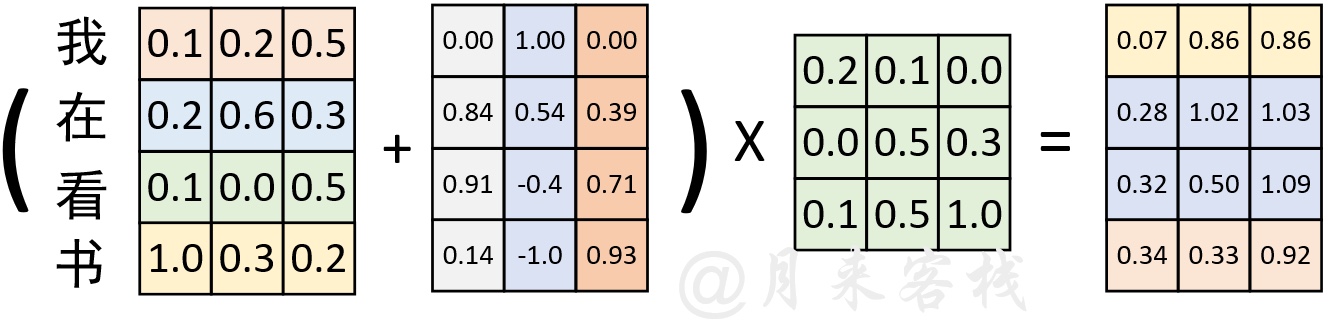
xxxxxxxxxx201class PositionalEncoding(nn.Module):2 def __init__(self, d_model, dropout=0.1, max_len=5000):3 super(PositionalEncoding, self).__init__()4 self.dropout = nn.Dropout(p=dropout)5 pe = torch.zeros(max_len, d_model) # [max_len, d_model]6 position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # [max_len, 1]7 div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))8 # [d_model/2]9 pe[:, 0::2] = torch.sin(position * div_term) # [max_len, d_model/2]10 pe[:, 1::2] = torch.cos(position * div_term)11 pe = pe.unsqueeze(0).transpose(0, 1) # [max_len, 1, d_model]12 self.register_buffer('pe', pe)1314 def forward(self, x):15 """16 :param x: [x_len, batch_size, emb_size]17 :return: [x_len, batch_size, emb_size]18 """19 x = x + self.pe[:x.size(0), :] # [x_len, batch_size, d_model]20 return self.dropout(x)如上代码所示便是整个Positional Embedding的实现过程,其中第5行代码是用来初始化一个全0的位置矩阵(也就是图1中从左往右数第2个矩阵),同时还指定了一个序列的最大长度;第6-10行是用来计算每个维度(每一列)的相关位置信息;第19行代码首先是在位置矩阵中取与输入序列长度相等的前x_len行,然后在加上Token Embedding的结果;第20行是用来返回最后得到的结果并进行Dropout操作。同时,这里需要注意的一点便是,在输入x的维度中batch_size并不是第1个维度。
2.3 Embedding代码示例
在实现完这部分代码后,便可以通过如下方式进行使用:
xxxxxxxxxx81if __name__ == '__main__':2 x = torch.tensor([[1, 3, 5, 7, 9], [2, 4, 6, 8, 10]], dtype=torch.long)3 x = x.reshape(5, 2) # [src_len, batch_size]4 token_embedding = TokenEmbedding(vocab_size=11, emb_size=512)5 x = token_embedding(tokens=x)6 pos_embedding = PositionalEncoding(d_model=512)7 x = pos_embedding(x=x)8 print(x.shape) # torch.Size([5, 2, 512])3 Transformer实现
在介绍完Embedding部分的编码工作后,下面就开始正式如何来实现Transformer网络结构。首先,对于Transformer网络的实现一共会包含4个部分:MyTransformerEncoderLayer、MyTransformerEncoder、MyTransformerDecoderLayer和MyTransformerDecoder。其分别表示定义一个单独编码层、构造由多个编码层组合得到的编码器、定义一个单独的解码层以及构造由多个解码层得到的解码器。
3.1 编码层的实现
首先,我们需要实现最基本的编码层单元,也就是如图2所示的前向传播过程(不包括Embedding部分)。
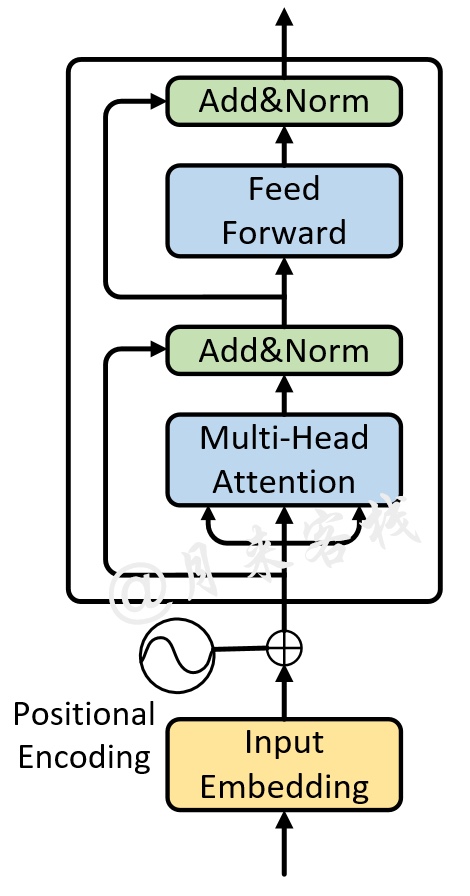
对于这部分前向传播过程,可以通过如下代码来进行实现:
xxxxxxxxxx201class MyTransformerEncoderLayer(nn.Module):2 def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):3 super(MyTransformerEncoderLayer, self).__init__()4 """5 :param d_model: d_k = d_v = d_model/nhead = 64, 模型中向量的维度,论文默认值为 5126 :param nhead: 多头注意力机制中多头的数量,论文默认为值 87 :param dim_feedforward: 全连接中向量的维度,论文默认值为 20488 :param dropout: 丢弃率,论文中的默认值为 0.1 9 """10 self.self_attn = MyMultiheadAttention(d_model, nhead, dropout=dropout)11 self.dropout1 = nn.Dropout(dropout)12 self.norm1 = nn.LayerNorm(d_model)1314 self.linear1 = nn.Linear(d_model, dim_feedforward)15 self.dropout = nn.Dropout(dropout)16 self.linear2 = nn.Linear(dim_feedforward, d_model)17 self.activation = F.relu1819 self.dropout2 = nn.Dropout(dropout)20 self.norm2 = nn.LayerNorm(d_model)在上述代码中,第10行用来定义一个多头注意力机制模块,并传入相应的参数(具体内容参加前一篇文章);第11-20行代码便是用来定义其它层归一化和线性变换的模块。在完成类MyTransformerEncoderLayer的初始化后,便可以实现整个前向传播的forward方法:
xxxxxxxxxx171 def forward(self, src, src_mask=None, src_key_padding_mask=None):2 """3 :param src: 编码部分的输入,形状为 [src_len,batch_size, embed_dim]4 :param src_mask: 编码部分输入的padding情况,形状为 [batch_size, src_len]5 :return: # [src_len, batch_size, num_heads * kdim] <==> [src_len,batch_size,embed_dim]6 """7 src2 = self.self_attn(src, src, src, attn_mask=src_mask,8 key_padding_mask=src_key_padding_mask, )[0] # 计算多头注意力9 # src2: [src_len,batch_size,num_heads*kdim] num_heads*kdim = embed_dim10 src = src + self.dropout1(src2) # 残差连接11 src = self.norm1(src) # [src_len,batch_size,num_heads*kdim]1213 src2 = self.activation(self.linear1(src)) # [src_len,batch_size,dim_feedforward]14 src2 = self.linear2(self.dropout(src2)) # [src_len,batch_size,num_heads*kdim]15 src = src + self.dropout2(src2)16 src = self.norm2(src)17 return src # [src_len, batch_size, num_heads * kdim] <==> [src_len,batch_size,embed_dim]在上述代码中,第7-8行便是用来实现图2中Multi-Head Attention部分的前向传播过程;第10-11行用来实现多头注意力后的Add&Norm部分;第13-16行用来实现图2中最上面的Feed Forward部分和Add&Norm部分。
这里再次提醒大家,在阅读代码的时候最好是将对应的维度信息带入以便于理解。
3.2 编码器实现
在实现完一个标准的编码层之后,便可以基于此来实现堆叠多个编码层,从而得到Transformer中的编码器。对于这部分内容,可以通过如下代码来实现:
xxxxxxxxxx151def _get_clones(module, N):2 return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])34class MyTransformerEncoder(nn.Module):5 def __init__(self, encoder_layer, num_layers, norm=None):6 super(MyTransformerEncoder, self).__init__()7 """8 encoder_layer: 就是包含有多头注意力机制的一个编码层9 num_layers: 克隆得到多个encoder layers 论文中默认为610 norm: 归一化层11 """12 self.layers = _get_clones(encoder_layer, num_layers) 13 # 克隆得到多个encoder layers 论文中默认为614 self.num_layers = num_layers15 self.norm = norm在上述代码中,第1-2行是用来定义一个克隆多个编码层或解码层功能函数;第12行中的encoder_layer便是一个实例化的编码层,self.layers中保存的便是一个包含有多个编码层的ModuleList。在完成类MyTransformerEncoder的初始化后,便可以实现整个前向传播的forward方法:
xxxxxxxxxx141 def forward(self, src, mask=None, src_key_padding_mask=None):2 """3 :param src: 编码部分的输入,形状为 [src_len,batch_size, embed_dim]4 :param mask: 编码部分输入的padding情况,形状为 [batch_size, src_len]5 :return:# [src_len, batch_size, num_heads * kdim] <==> [src_len,batch_size,embed_dim]6 """7 output = src8 for mod in self.layers:9 output = mod(output, src_mask=mask,10 src_key_padding_mask=src_key_padding_mask) 11 # 多个encoder layers层堆叠后的前向传播过程12 if self.norm is not None:13 output = self.norm(output)14 return output # [src_len, batch_size, num_heads * kdim] <==> [src_len,batch_size,embed_dim]在上述代码中,第8-10行便是用来实现多个编码层堆叠起来的效果,并完成整个前向传播过程;第11-13行用来对多个编码层的输出结果进行层归一化并返回最终的结果。
3.3 编码器使用示例
在完成Transformer中编码器的实现过程后,便可以将其用于对输入序列进行编码。例如可以仅仅通过一个编码器对输入序列进行编码,然后将最后的输出喂入到分类器当中进行分类处理,这部分内容在后续也会进行介绍。下面先看一个使用示例。
xxxxxxxxxx171if __name__ == '__main__':2 src_len = 53 batch_size = 24 dmodel = 325 num_head = 36 num_layers = 27 src = torch.rand((src_len, batch_size, dmodel)) # shape: [src_len, batch_size, embed_dim]8 src_key_padding_mask = torch.tensor([[True, True, True, False, False],9 [True, True, True, True, False]]) # shape: [batch_size, src_len]10 11 my_transformer_encoder_layer = MyTransformerEncoderLayer(d_model=dmodel, nhead=num_head)12 my_transformer_encoder = MyTransformerEncoder(encoder_layer=my_transformer_encoder_layer,13 num_layers=num_layers,14 norm=nn.LayerNorm(dmodel))15 memory = my_transformer_encoder(src=src, mask=None, 16 src_key_padding_mask=src_key_padding_mask)17 print(memory.shape) # torch.Size([5, 2, 32])在上述代码中,第2-6行定义了编码器中各个部分的参数值;第11-12行则是首先定义一个编码层,然后再定义由多个编码层组成的编码器;第15-16行便是用来得到整个编码器的前向传播输出结果,并且需要注意的是在编码器中不需要掩盖当前时刻之后的位置信息,所以mask=None。
3.4 解码层的实现
在介绍完编码器的实现后,下面就开始介绍如何实现Transformer中的解码器部分。同编码器的实现流程一样,首先需要实现的依旧是一个标准的解码层,也就是图3所示的前向传播过程(不包括Embedding部分)。
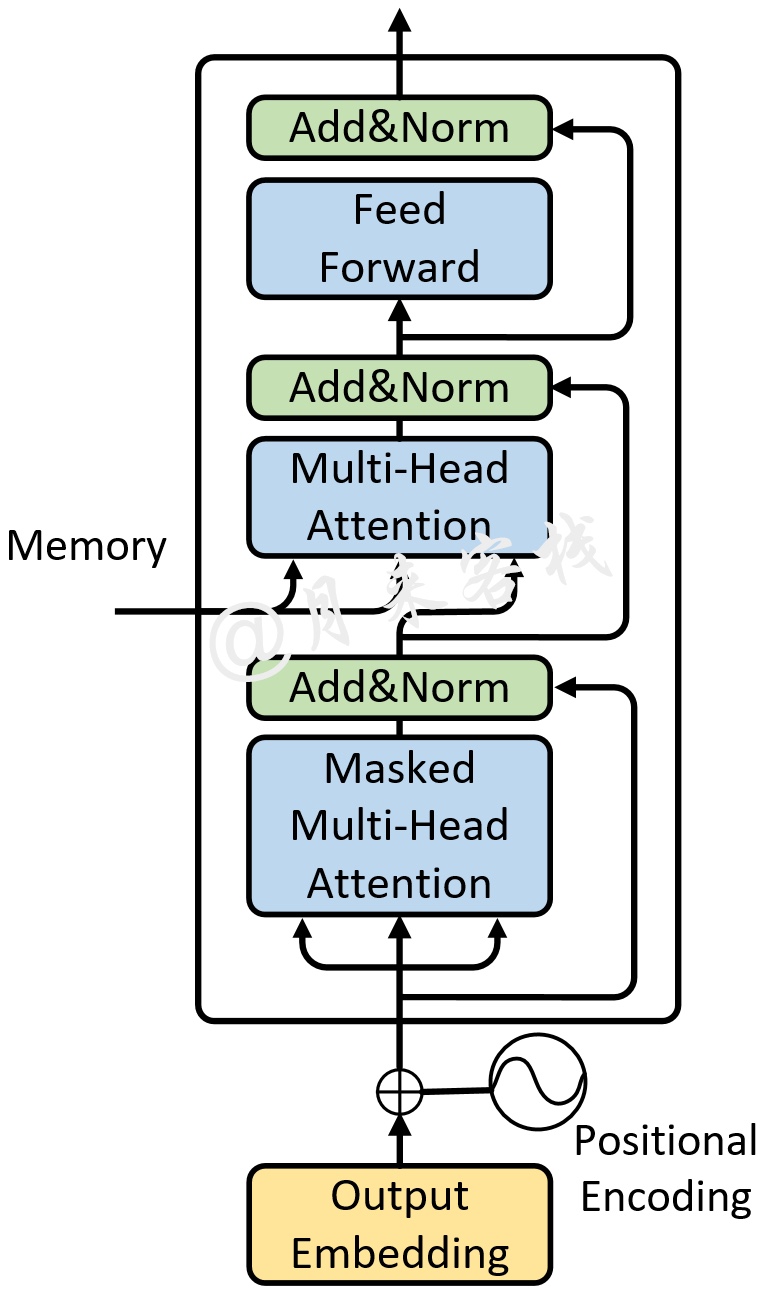
对于这部分前向传播过程,可以通过如下代码来进行实现:
xxxxxxxxxx241class MyTransformerDecoderLayer(nn.Module):2 def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):3 super(MyTransformerDecoderLayer, self).__init__()4 """5 :param d_model: d_k = d_v = d_model/nhead = 64, 模型中向量的维度,论文默认值为 5126 :param nhead: 多头注意力机制中多头的数量,论文默认为值 87 :param dim_feedforward: 全连接中向量的维度,论文默认值为 20488 :param dropout: 丢弃率,论文中的默认值为 0.1 9 """10 self.self_attn = MyMultiheadAttention(embed_dim=d_model, num_heads=nhead, dropout=dropout)11 # 解码部分输入序列之间的多头注意力(也就是论文结构图中的Masked Multi-head attention)12 self.multihead_attn = MyMultiheadAttention(embed_dim=d_model, num_heads=nhead, dropout=dropout)13 # 编码部分输出(memory)和解码部分之间的多头注意力机制。14 self.linear1 = nn.Linear(d_model, dim_feedforward)15 self.dropout = nn.Dropout(dropout)16 self.linear2 = nn.Linear(dim_feedforward, d_model)1718 self.norm1 = nn.LayerNorm(d_model)19 self.norm2 = nn.LayerNorm(d_model)20 self.norm3 = nn.LayerNorm(d_model)21 self.dropout1 = nn.Dropout(dropout)22 self.dropout2 = nn.Dropout(dropout)23 self.dropout3 = nn.Dropout(dropout)24 self.activation = F.relu在上述代码中,第10行代码用来定义图3中Masked Multi-head Attention部分的前向传播过程;第12行则是用来定义图3中编码器与解码器交互的多头注意力机制模块;第14-24行是用来定义剩余的全连接层以及层归一化相关操作。在完成类MyTransformerDecoderLayer的初始化后,便可以实现整个前向传播的forward方法:
xxxxxxxxxx311 def forward(self, tgt, memory, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None,2 memory_key_padding_mask=None):3 """4 :param tgt: 解码部分的输入,形状为 [tgt_len,batch_size, embed_dim]5 :param memory: 编码部分的输出(memory), [src_len,batch_size,embed_dim]6 :param tgt_mask: 注意力Mask输入,用于掩盖当前position之后的信息, [tgt_len, tgt_len]7 :param memory_mask: 编码器-解码器交互时的注意力掩码,一般为None8 :param tgt_key_padding_mask: 解码部分输入的padding情况,形状为 [batch_size, tgt_len]9 :param memory_key_padding_mask: 编码部分输入的padding情况,形状为 [batch_size, src_len]10 :return:# [tgt_len, batch_size, num_heads * kdim] <==> [tgt_len,batch_size,embed_dim]11 """12 tgt2 = self.self_attn(tgt, tgt, tgt, # [tgt_len,batch_size, embed_dim]13 attn_mask=tgt_mask,14 key_padding_mask=tgt_key_padding_mask)[0]15 # 解码部分输入序列之间的多头注意力(也就是论文结构图中的Masked Multi-head attention)16 tgt = tgt + self.dropout1(tgt2) # 接着是残差连接17 tgt = self.norm1(tgt) # [tgt_len,batch_size, embed_dim]1819 tgt2 = self.multihead_attn(tgt, memory, memory, # [tgt_len, batch_size, embed_dim]20 attn_mask=memory_mask,21 key_padding_mask=memory_key_padding_mask)[0]22 # 解码部分的输入经过多头注意力后同编码部分的输出(memory)通过多头注意力机制进行交互23 tgt = tgt + self.dropout2(tgt2) # 残差连接24 tgt = self.norm2(tgt) # [tgt_len, batch_size, embed_dim]2526 tgt2 = self.activation(self.linear1(tgt)) # [tgt_len, batch_size, dim_feedforward]27 tgt2 = self.linear2(self.dropout(tgt2)) # [tgt_len, batch_size, embed_dim]28 # 最后的两层全连接29 tgt = tgt + self.dropout3(tgt2)30 tgt = self.norm3(tgt)31 return tgt # [tgt_len, batch_size, num_heads * kdim] <==> [tgt_len,batch_size,embed_dim]在上述代码中,第12-14行用来完成图3中Masked Multi-head Attention部分的前向传播过程,其中的tgt_mask就是在训练时用来掩盖当前时刻之后位置的注意力掩码;第16-17行用来完成图3中Masked Multi-head Attention之后Add&Norm部分的前向传播过程;第19-21行用来实现解码器与编码器之间的交互过程,其中memory_mask为None,memory_key_padding_mask为src_key_padding_mask用来对编码器的输出进行(序列)填充部分的掩盖,这一点同编码器中的key_padding_mask原理一样;第23-31行便是用来实现余下的其它过程。
3.5 解码器实现
在实现完一个标准的解码层之后,便可以基于此来实现堆叠多个解码层,从而得到Transformer中的解码器。对于这部分内容,可以通过如下代码来实现:
x
1class MyTransformerDecoder(nn.Module):2 def __init__(self, decoder_layer, num_layers, norm=None):3 super(MyTransformerDecoder, self).__init__()4 self.layers = _get_clones(decoder_layer, num_layers)5 self.num_layers = num_layers6 self.norm = norm78 def forward(self, tgt, memory, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None,9 memory_key_padding_mask=None):10 """11 :param tgt: 解码部分的输入,形状为 [tgt_len,batch_size, embed_dim]12 :param memory: 编码部分最后一层的输出 [src_len,batch_size, embed_dim]13 :param tgt_mask: 注意力Mask输入,用于掩盖当前position之后的信息, [tgt_len, tgt_len]14 :param memory_mask: 编码器-解码器交互时的注意力掩码,一般为None15 :param tgt_key_padding_mask: 解码部分输入的padding情况,形状为 [batch_size, tgt_len]16 :param memory_key_padding_mask: 编码部分输入的padding情况,形状为 [batch_size, src_len]17 :return: # [tgt_len, batch_size, num_heads * kdim] <==> [tgt_len,batch_size,embed_dim]18 """19 output = tgt # [tgt_len,batch_size, embed_dim]20 for mod in self.layers: # 这里的layers就是N层解码层堆叠起来的21 output = mod(output, memory,22 tgt_mask=tgt_mask,23 memory_mask=memory_mask,24 tgt_key_padding_mask=tgt_key_padding_mask,25 memory_key_padding_mask=memory_key_padding_mask)26 if self.norm is not None:27 output = self.norm(output)28 return output # [tgt_len, batch_size, num_heads * kdim] <==> [tgt_len,batch_size,embed_dim]在上述代码中,第4行用来克隆得到多个解码层;第20-25行用来实现多层解码层的前向传播过程;第28行便是用来返回最后的结果。
3.6 Transformer网络实现
在实现完Transformer中各个基础模块的话,下面就可以来搭建最后的Transformer模型了。总体来说这部分的代码也相对简单,只需要将上述编码器解码器组合到一起即可,具体代码如下所示:
x
1class MyTransformer(nn.Module):2 def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,3 num_decoder_layers=6, dim_feedforward=2048, dropout=0.1):4 super(MyTransformer, self).__init__()56 """7 :param d_model: d_k = d_v = d_model/nhead = 64, 模型中向量的维度,论文默认值为 5128 :param nhead: 多头注意力机制中多头的数量,论文默认为值 89 :param num_encoder_layers: encoder堆叠的数量,也就是论文中的N,论文默认值为610 :param num_decoder_layers: decoder堆叠的数量,也就是论文中的N,论文默认值为611 :param dim_feedforward: 全连接中向量的维度,论文默认值为 204812 :param dropout: 丢弃率,论文中的默认值为 0.113 """14 # ================ 编码部分 =====================15 encoder_layer = MyTransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout)16 encoder_norm = nn.LayerNorm(d_model)17 self.encoder = MyTransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)18 # ================ 解码部分 =====================19 decoder_layer = MyTransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout)20 decoder_norm = nn.LayerNorm(d_model)21 self.decoder = MyTransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)22 self._reset_parameters() # 初始化模型参数23 self.d_model = d_model24 self.nhead = nhead在上述代码中,第15-17行是用来定义编码器部分;第19-21行是用来定义解码器部分;第22行用来以某种方式初始化Transformer中的权重参数,具体实现在稍后的内容中。在定义完类MyTransformer的初始化函数后,便可以来实现Transformer的整个前向传播过程,代码如下:
xxxxxxxxxx201 def forward(self, src, tgt, src_mask=None, tgt_mask=None,2 memory_mask=None, src_key_padding_mask=None,3 tgt_key_padding_mask=None, memory_key_padding_mask=None):4 """5 :param src: [src_len,batch_size,embed_dim]6 :param tgt: [tgt_len, batch_size, embed_dim]7 :param src_mask: None8 :param tgt_mask: [tgt_len, tgt_len]9 :param memory_mask: None10 :param src_key_padding_mask: [batch_size, src_len]11 :param tgt_key_padding_mask: [batch_size, tgt_len]12 :param memory_key_padding_mask: [batch_size, src_len]13 :return: [tgt_len, batch_size, num_heads * kdim] <==> [tgt_len,batch_size,embed_dim]14 """15 memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)16 # [src_len, batch_size, num_heads * kdim] <==> [src_len,batch_size,embed_dim]17 output = self.decoder(tgt=tgt, memory=memory, tgt_mask=tgt_mask, memory_mask=memory_mask,18 tgt_key_padding_mask=tgt_key_padding_mask,19 memory_key_padding_mask=memory_key_padding_mask)20 return output # [tgt_len, batch_size, num_heads * kdim] <==> [tgt_len,batch_size,embed_dim]在上述代码中,src表示编码器的输入;tgt表示解码器的输入;src_mask为空,因为编码时不需要对当前时刻之后的位置信息进行掩盖;tgt_mask用于掩盖解码输入中当前时刻以后的所有位置信息;memory_mask为空;src_key_padding_mask表示对编码输入序列填充部分的Token进行mask;tgt_key_padding_mask表示对解码输入序列填充部分的Token进行掩盖;memory_key_padding_mask表示对编码器的输出部分进行掩盖,掩盖原因等同于编码输入时的mask操作。
到此,对于整个Transformer的网络结构就算是搭建完毕了,不过这还没有实现论文中基于Transformer结构的翻译模型,而这部分内容笔者也将会在下一篇文章中进行详细的介绍。当然,出了上述模块之外,Transformer中还有两个部分需要实现的就是参数初始化方法和注意力掩码矩阵生成方法,具体代码如下:
x
1 def _reset_parameters(self):2 for p in self.parameters():3 if p.dim() > 1:4 xavier_uniform_(p)5 6 def generate_square_subsequent_mask(self, sz):7 mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)8 mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))9 return mask # [sz,sz]3.7 Transfromer使用示例
在实现完Transformer的整个完了结构后,便可以通过如下步骤进行使用:
x
1if __name__ == '__main__':2 src_len = 53 batch_size = 24 dmodel = 325 tgt_len = 66 num_head = 87 src = torch.rand((src_len, batch_size, dmodel)) # shape: [src_len, batch_size, embed_dim]8 src_key_padding_mask = torch.tensor([[True, True, True, False, False],9 [True, True, True, True, False]]) # shape: [batch_size, src_len]1011 tgt = torch.rand((tgt_len, batch_size, dmodel)) # shape: [tgt_len, batch_size, embed_dim]12 tgt_key_padding_mask = torch.tensor([[True, True, True, False, False, False],13 [True, True, True, True, False, False]]) # shape: [batch_size, tgt_len]14 15 my_transformer = MyTransformer(d_model=dmodel, nhead=num_head, num_encoder_layers=6,16 num_decoder_layers=6, dim_feedforward=500)17 tgt_mask = my_transformer.generate_square_subsequent_mask(tgt_len)18 out = my_transformer(src=src, tgt=tgt, tgt_mask=tgt_mask,19 src_key_padding_mask=src_key_padding_mask,20 tgt_key_padding_mask=tgt_key_padding_mask,21 memory_key_padding_mask=src_key_padding_mask)22 print(out.shape) #torch.Size([6, 2, 32])在上述代码中,第7-13行用来生成模拟的输入数据;第15-16行用来实例化类MyTransformer;第17行用来生成解码输入时的注意力掩码矩阵;第18-21行用来执行Transformer网络结构的前向传播过程。
4 总结
在这篇文章中,笔者首先介绍了Embedding部分代码的实现,包括Token Embedding和Positional Embedding;接着分别详细介绍了编码层的实现过程、编码器的实现过程、编码器的使用示例、解码层的实现过程、解码器的实现过程以及整个Transformer的实现过程等;最后通过一个示例来介绍了如何使用类MyTransformer。在下一篇文中,笔者将会基于现在实现的MyTransformer类来搭建一个真实的文本翻译模型,以便更加清楚的理解Transformer的工作流程。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎分享至一位你的朋友!若有任何疑问与建议,请添加笔者微信'nulls8'或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1] LANGUAGE TRANSLATION WITH TRANSFORMER https://pytorch.org/tutorials/beginner/translation_transformer.html
[2] The Annotated Transformer http://nlp.seas.harvard.edu/2018/04/03/attention.html
[3] SEQUENCE-TO-SEQUENCE MODELING WITH NN.TRANSFORMER AND TORCHTEXT https://pytorch.org/tutorials/beginner/transformer_tutorial.html
[4] Transformer model for language understandinghttps://tensorflow.google.cn/text/tutorials/transformer?hl=en#multi-head_attention
[5] 代码仓库 https://github.com/moon-hotel/TransformerTranslation
推荐阅读
[1] This post is all you need(①多头注意力机制原理)


