1 引言
各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
在网络模型的训练过程中,通常我们都需要观察其损失值或准确率的变化趋势来确定模型的优化方向,例如学习率的动态调整、惩罚项系数等等。同时,对于图像处理方向的朋友来说可能还希望能够可视化模型的特征图或者是样本分类类别在空间中的分布情况等。虽然这些结果我们可以在网络训练结果后取对应的变量通过matplotlib进行可视化,但是我们更希望的是在模型训练的过程中就对其各种状态进行可视化。
因此,对于上述需求我们可以借助谷歌开源的Tensorboard工具来进行实现。在本篇文章中,掌柜将会详细介绍如何在PyTorch中通过Tensorboard来对各类变量及指标进行可视化。
本文中的所有示例代码均可从此仓库获取: https://github.com/moon-hotel/DeepLearningWithMe
2 安装与调试Tensorboard
如果需要在PyTorch中使用Tensorboard除了需要安装Tensorboard工具本身之外,还需要安装的便是TensorFlow本身。因为Tensorboard在使用中会依赖于TensorFlow框架。
2.1 安装与启动
对于TensorFlow和Tensorboard的安装,我们只需要执行安装TensorFlow的命令便可以同时完成两者的安装:
xxxxxxxxxx11pip install tensorflow
同时,由于我们只是借助于Tensorboard来进行可视化,因此在安装TensorFlow的时候不用区分是GPU还是CPU版本的,掌柜测试了都可以。也就是说假如你在某台主机上装了GPU版本的PyTorch,而不管你是装的GPU版还是CPU版的TensorFlow,Tensorboard都可以正常使用。
在安装成功之后通过可以通过如下命令来进行测试:
xxxxxxxxxx11tensorboard --logdir=runs并会出现如下提示:
xxxxxxxxxx11TensorBoard 1.15.0 at http://localhost:6006/ (Press CTRL+C to quit)也就是说此时我们便可以通过127.0.0.1:6006这个链接来访问Tensorboard的可视化页面,如图1所示:
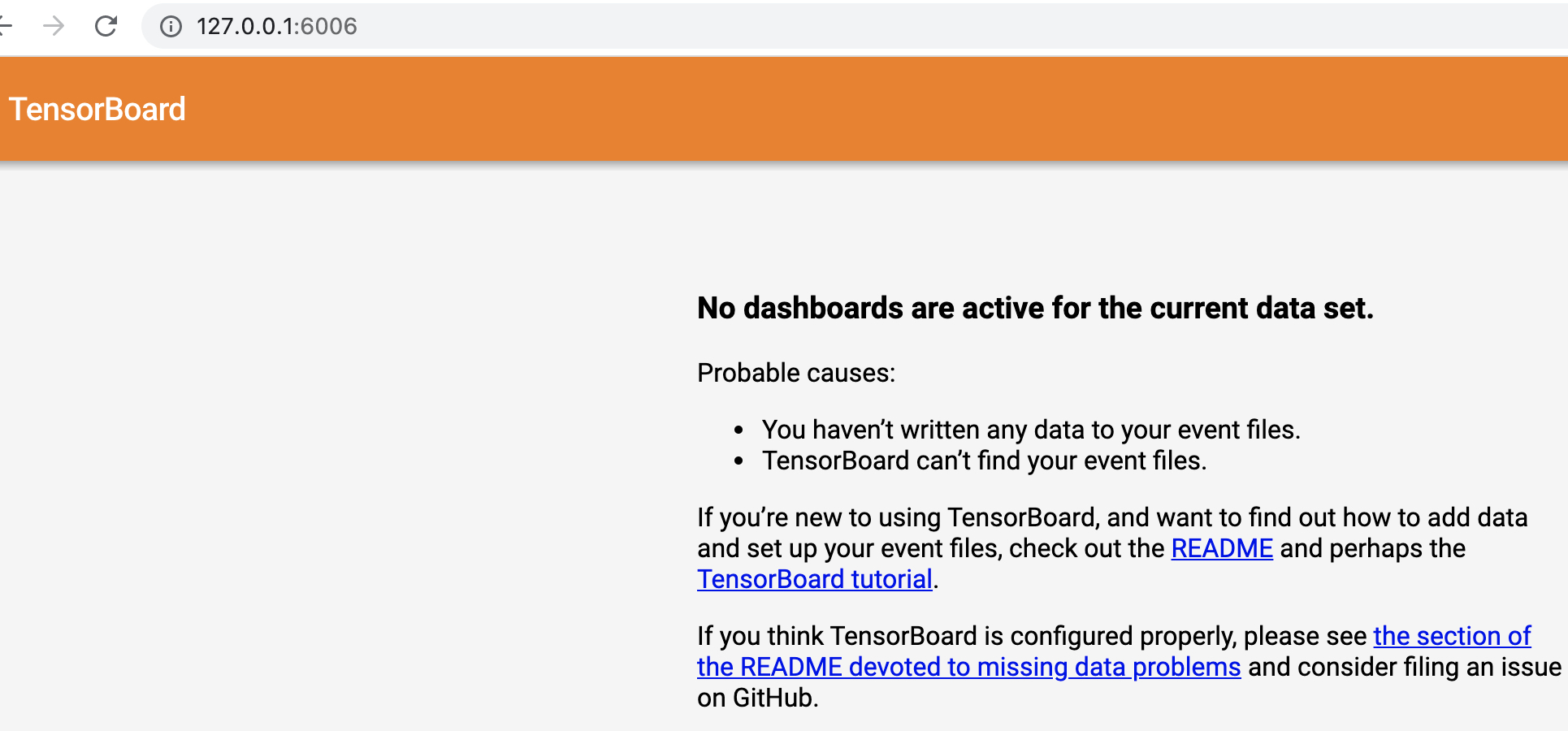
如果你发现打不开这里地址,那么可以尝试通过如下命令来进行启动,然后再通过127.0.0.1:6006这个链接来访问。
xxxxxxxxxx11tensorboard --logdir=runs --host 0.0.0.0命令中的--logdir用来指定可视化文件的目录地址,后续掌柜会详细介绍。
2.2 远程连接
上面掌柜介绍了如何在本地安装与启动Tensoboard,但是更常见的一种场景便是在远程主机上运行代码,但是需要在本地电脑上查看可视化的运行结果。如果需要实现这种目的通常来说有两种方法,下面掌柜就来分别进行介绍。
2.2.1 通过IP直接访问
在通过IP直接访问的方案中,不管你是在类似于腾讯云或阿里云上租用的主机还是实验室的专用主机,在根据2.1节中的步骤完成Tensoboard安装并启动后,你在自己电脑上都可以通过主机IP来进行访问,例如:
xxxxxxxxxx11http://IP:6006需要注意的是,上面的IP对于公网主机(如腾讯云)来说指的是主机的公网IP,对于实验室或学校的主机来说指的则是局域网的内网IP。同时,如果在主机上启动Tensoboard后发现在本地并不能够打开,那么可以通过如下方式来进行排查:
公网主机
- 在后台的安全策略里面查看一下
6006这个端口有没有被打开,如果没有则需要打开; - 查看IP是否为公网IP,在主机的后台管理页面可以看到。
- 在后台的安全策略里面查看一下
局域网主机
查看本地电脑是否和主机处于同一网段;
查看主机的6006端口是否打开,如果没有可以通过如下命令打开
xxxxxxxxxx41firewall-cmd --zone=public --list-ports # 查看已开放端口2firewall-cmd --zone=public --add-port=5672/tcp --permanent #开放5672端口3firewall-cmd --zone=public --remove-port=5672/tcp --permanent #关闭56724firewall-cmd --reload # 配置立即生效
2.2.2 通过SSH转发访问
当然,除了通过直接IP访问之外,我们还可以借助SSH反向隧道技术来进行访问,例如服务器只开了22端口而且你没有权限打开其它端口的情况。在这种情况下,你可以通过下面两种方式来进行远程连接:
命令行终端
如果你的命令行终端支持SSH命令(例如较新的Windows10 的CMD或者Linux等)的话,那么可以直接通过下面这一条命令来进行连接:
xxxxxxxxxx11ssh -L 16006:127.0.0.1:6006 username@ip这条命令的含义就是将服务器上6006端口的信息通过SSH转发到本地的16006端口,其中16006是本地的任意端口(无限制),只要不和本地应用有冲突就行;后面则是对应的用户名和IP。
上述命令连接成功并根据2.1节中的命令启动Tensorboard之后,在本地通过浏览器打开如下地址即可:
xxxxxxxxxx11http://127.0.0.1:16006Xshell工具
如果你的电脑终端不支持SSH命令的话,那么你还可以通过Xshell工具来实现SSH反向代理。首先你需要安装好Xshell工具,没有的话可以参考这篇文章进行安装。在安装完成后按照如下步骤配置即可:
第一步:新建连接
如图2所示,点击新建连接。
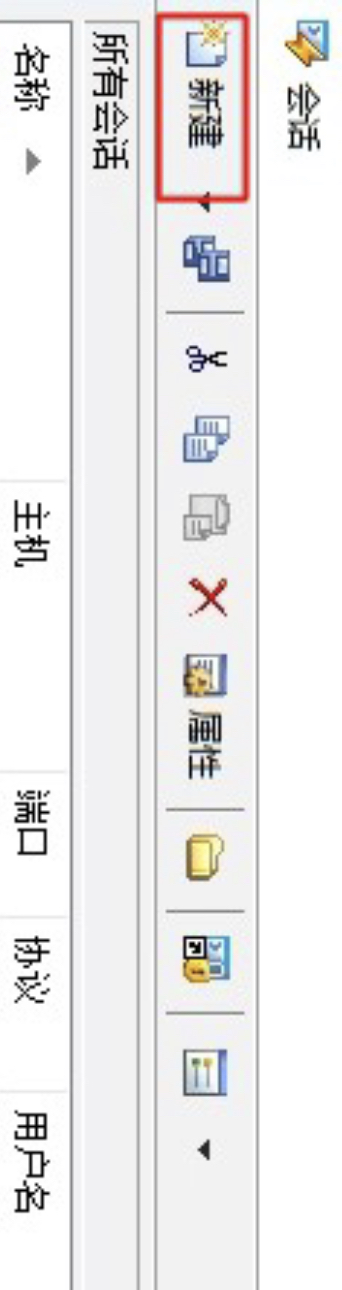
图 2. 新建连接(一) 然后再根据图3所示的界面配置主机信息。
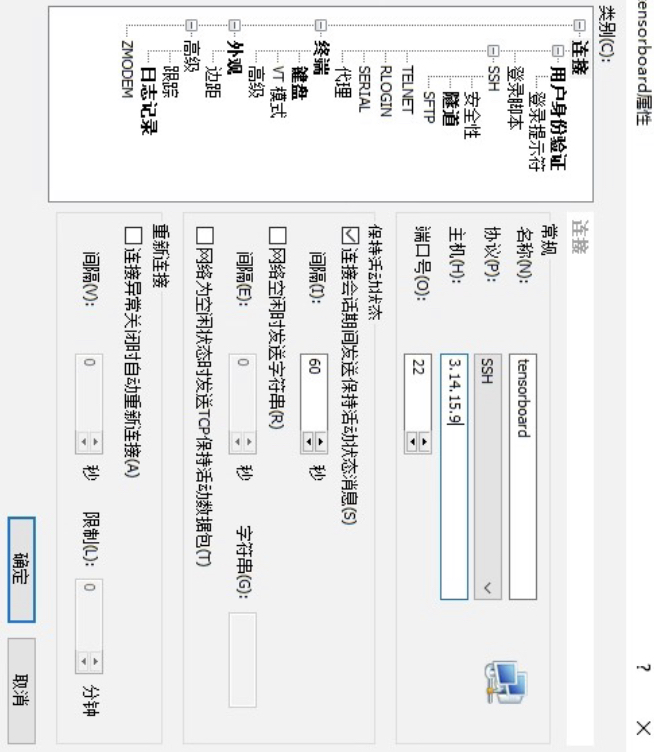
图 3. 新建连接(二) 第二步:配置代理
进一步,如图4所示点击侧边栏的隧道,并点击右侧的添加按钮。
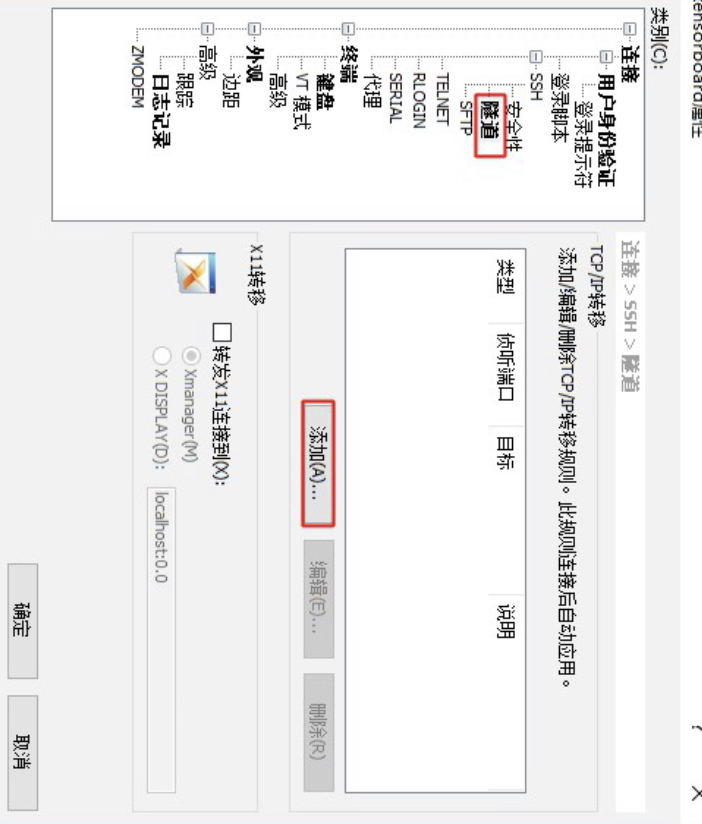
图 4. 配置代理(一) 接着再根据图5所示的示例进行端口代理配置。
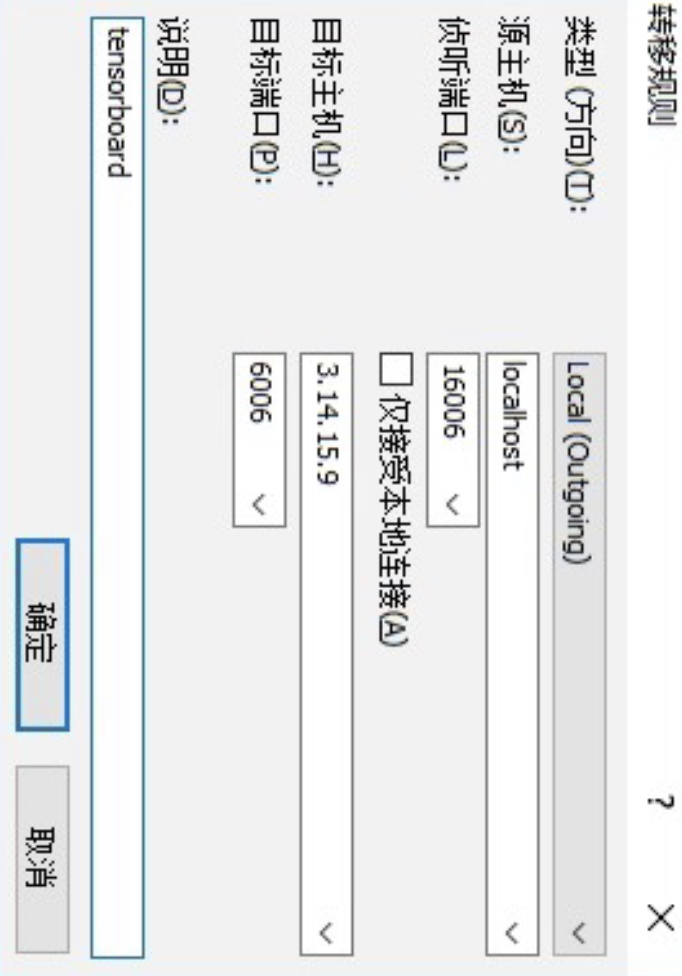
图 5. 配置代理(二) 配置完成后点击图6中的确认即可。
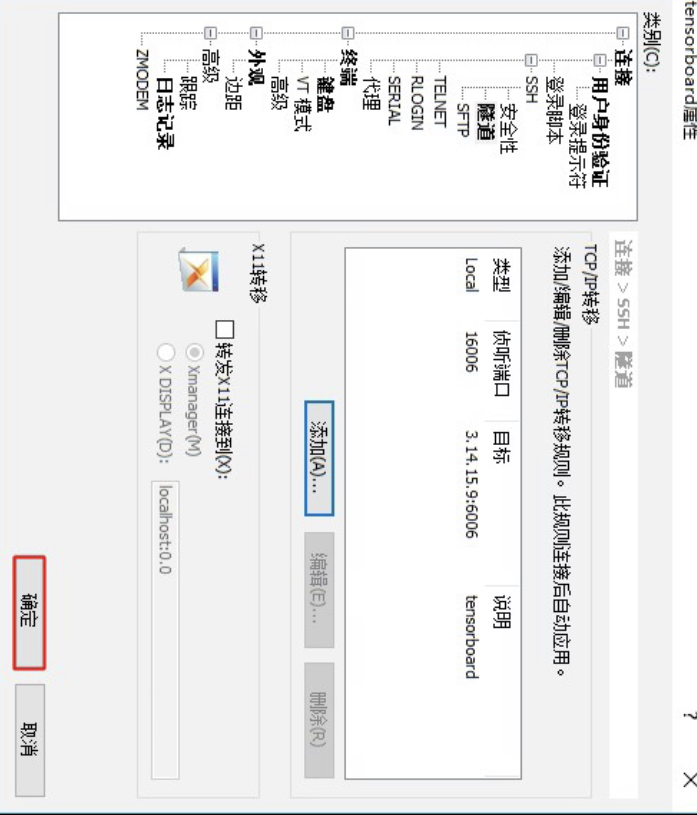
图 6. 配置代理(三) 完成上述两步配置之后,再双击刚刚这个新建的连接输入用户名和密码之后即可登录到主机并对相应的端口进行了监听与转发。最后我们同样只需要先在当前的命令行中启动Tensorboard,再在本地浏览器中通过如下地址进行访问即可:
xxxxxxxxxx11http://127.0.0.1:16006
3 使用Tensoboard
下面,掌柜将先通过一个简单的示例来展示如何可视化标量数据并在Tensoboard中进行显示;然后再来依次介绍一些常用的可视化方法。
3.1 add_scalar方法
这个方法通常用来可视化网络训练时的各类标量参数,例如损失、学习率和准确率等。如下便是add_scalar方法的使用示例:
xxxxxxxxxx91from torch.utils.tensorboard import SummaryWriter2if __name__ == '__main__': 3 writer = SummaryWriter(log_dir="runs/result_1", flush_secs=120)4 for n_iter in range(100):5 writer.add_scalar(tag='Loss/train',6 scalar_value=np.random.random(),7 global_step=n_iter)8 writer.add_scalar('Loss/test', np.random.random(), n_iter)9 writer.close()在上述代码中,第1行用来导入相关的可视化模块;第3行是实例化一个可视化类对象,log_dir用于指定可视化数据的保存路径,flush_secs表示指定多少秒将数据写入到本地一次(默认为120秒);第5-7行则是利用add_scalar方法来对相关标量进行可视化,其中tag表示对应的标签信息。
在上述代码运行之前,先进入到该代码文件所在的目录,然后运行如下命令来启动Tensoboard:
xxxxxxxxxx31tensorboard --logdir=runs2
3TensorBoard 1.15.0 at http://localhost:6006/ (Press CTRL+C to quit)可以看出,logdir后面的参数就是上面代码第3行里的参数。同时,根据提示在浏览器中打开上述链接便可以看到如图1所示的界面。
接着开始运行上述程序,此时便会在当前目录中生成如图7所示的文件(夹),其中result_1便是前面所指定的子目录,而以events.out开始的文件则是生成的可视化数据文件。
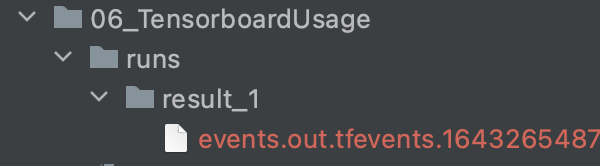
当程序运行时Tensoboard便会加载图7中所示的文件并在网页端进行渲染,如图8所示:
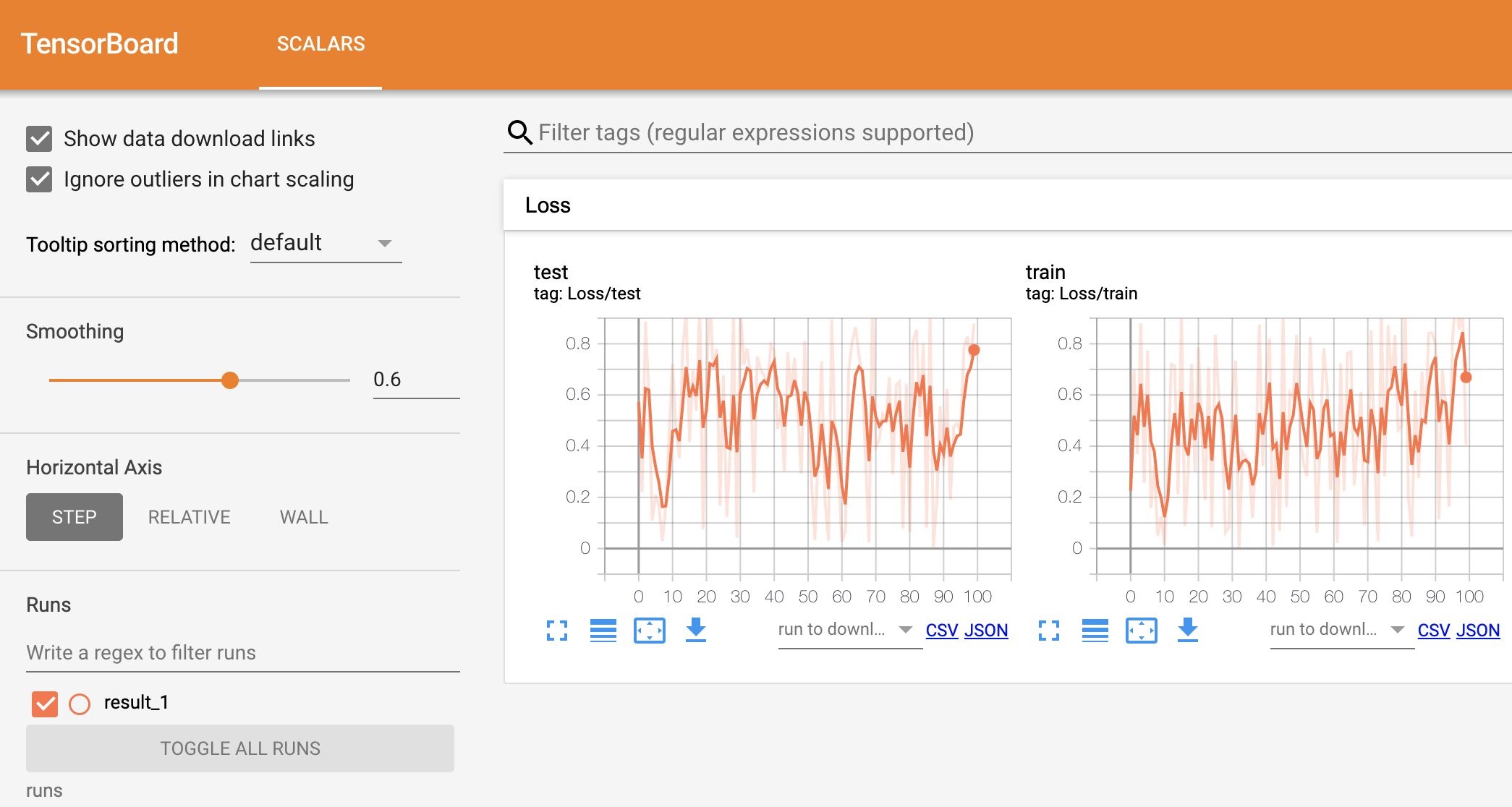
如图8所示为Tensoboard的可视化结果图,其中右边的Loss标签就是上面第5行代码中指定的Loss/train参数的前缀部分,也就是说如果想把若干个图放到一个标签下,那么就要保持其前缀一致,例如这里的Loss/train和Loss/test这两个图都将被放在Loss这个标签下。同时,在勾选左上角的"Show data download links"后,还能点击图片下方的按钮来分别下载SVG矢量图、原始图片的CSV或JSON数据。
在图8的左边部分,Smoothing参数用来调整右侧可视化结果的平滑度;Horizontal Axis用来切换不同的显示模式;Runs下面用来勾选需要可视化的结果,例如后续在初始化SummaryWriter()时指定log_dir="runs/result_2",那么在result_1下方便会再出现一个result_2的选项,这时我们可以选择多个结果同时可视化展示。
下面,掌柜开始逐一介绍几个常用的可视化方法。
3.2 add_graph方法
从名字可以看出add_graph方法是用于可视化模型的网络结构图,其用法示例如下:
xxxxxxxxxx51import torchvision2def add_graph(writer):3 img = torch.rand([1, 3, 64, 64], dtype=torch.float32)4 model = torchvision.models.AlexNet(num_classes=10)5 writer.add_graph(model, input_to_model=img) # 类似于TensorFlow 1.x 中的fed为了示例简洁,掌柜这里又把SummaryWriter()中的add_graph方法写成了一个函数。在上述代码中,第4行用于返回一个网络模型;第5行则是对网络结构图进行可视化,其中input_to_model参数为模型所接收的输入,这类似于TensorFlow中的fed_dict参数。
上述代码开始运行之后,便可以在网页端看到如下所示的可视化结果:
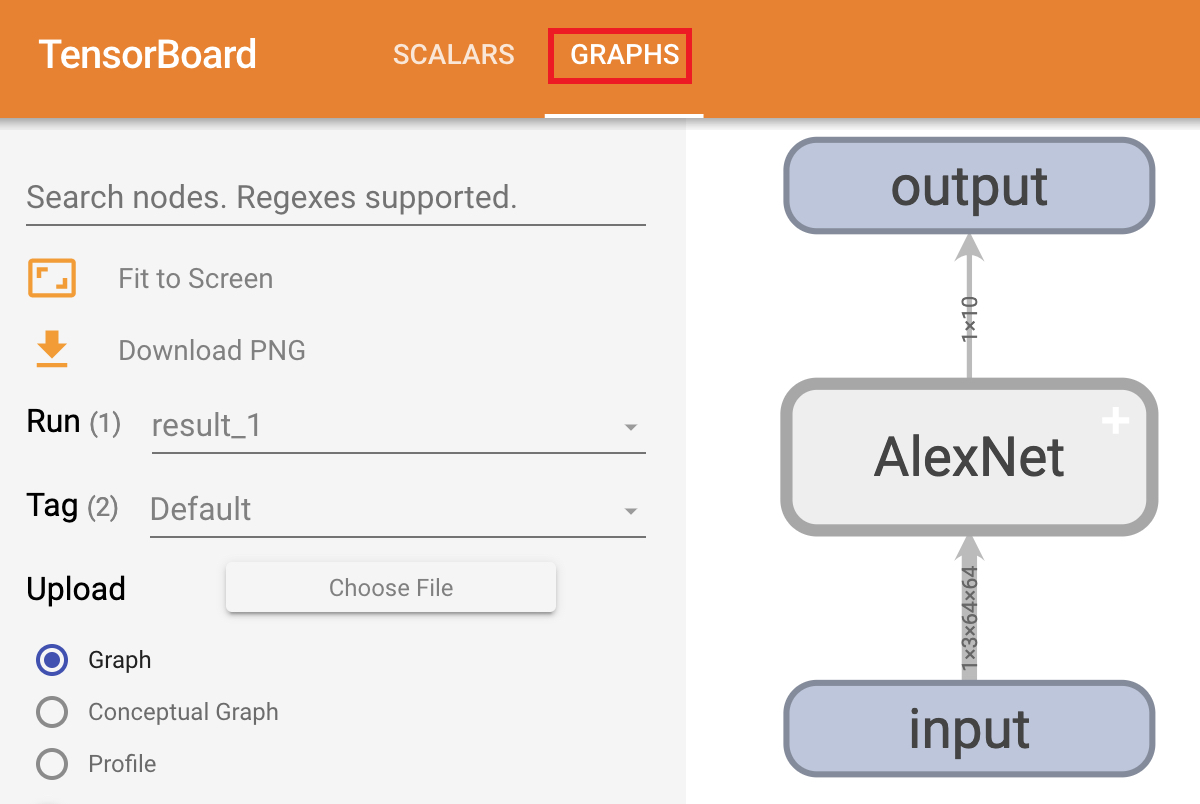
如图9所示便是可视化后的网络结构图,对于右侧网络结构中的每个模块都可以双击进行展开,而左边则是相关模式的切换。
3.3 add_scalars方法
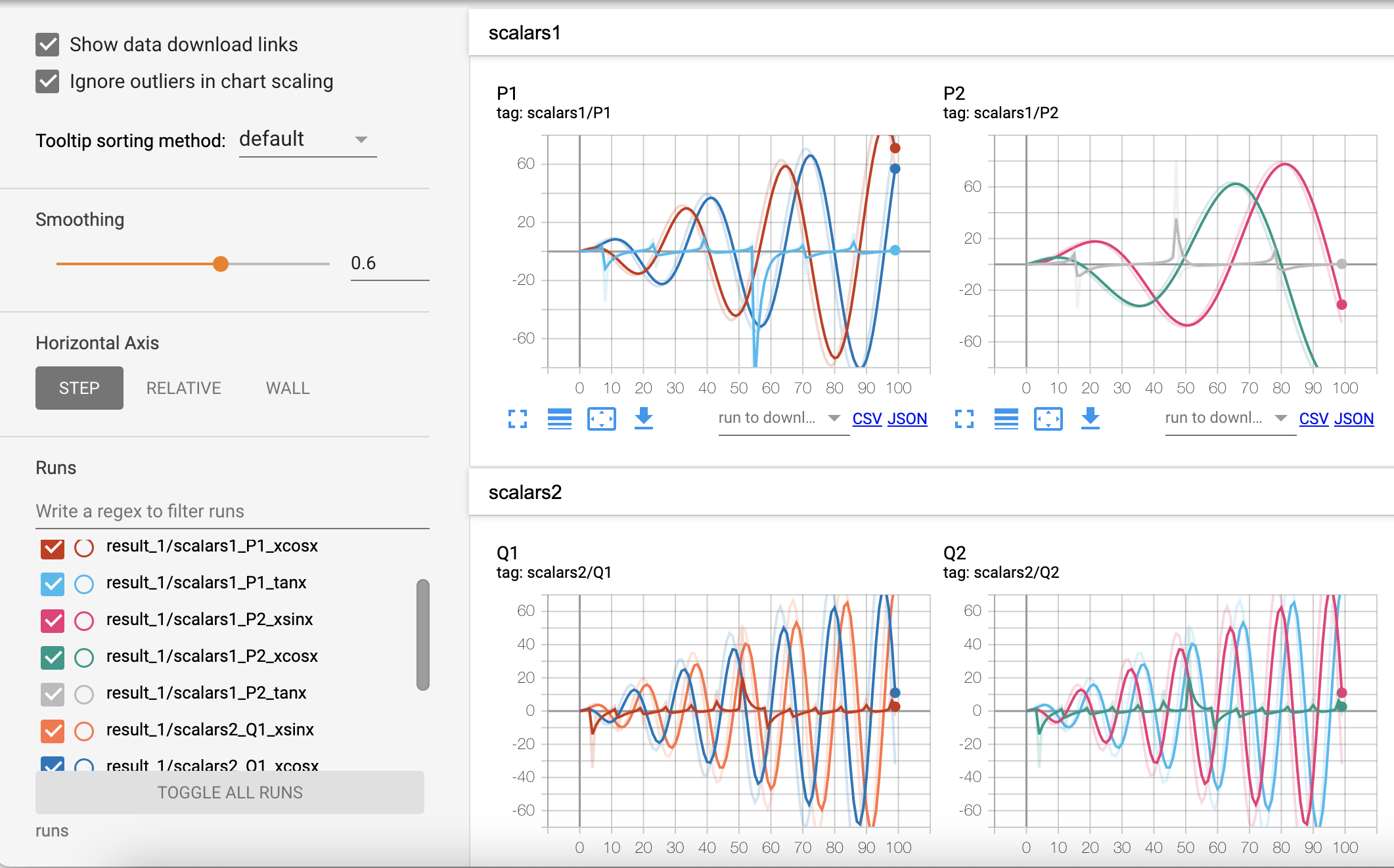
这个方法与add_scalar的差别在于add_scalars在一张图中可以绘制多个曲线,我们只需要以字典的形式传入参数即可,如下为add_scalars方法的使用示例:
xxxxxxxxxx211def add_scalars(writer):2 r = 53 for i in range(100):4 writer.add_scalars(main_tag='scalars1/P1',5 tag_scalar_dict={'xsinx': i * np.sin(i / r),6 'xcosx': i * np.cos(i / r),7 'tanx': np.tan(i / r)},8 global_step=i)9 writer.add_scalars('scalars1/P2',10 {'xsinx': i * np.sin(i / (2 * r)),11 'xcosx': i * np.cos(i / (2 * r)),12 'tanx': np.tan(i / (2 * r))}, i)13 writer.add_scalars(main_tag='scalars2/Q1',14 tag_scalar_dict={'xsinx': i * np.sin((2 * i) / r),15 'xcosx': i * np.cos((2 * i) / r),16 'tanx': np.tan((2 * i) / r)},17 global_step=i)18 writer.add_scalars('scalars2/Q2',19 {'xsinx': i * np.sin(i / (0.5 * r)),20 'xcosx': i * np.cos(i / (0.5 * r)),21 'tanx': np.tan(i / (0.5 * r))}, i)在上述代码中,掌柜一共画了4个图,分别对应代码中的4个add_scalars;同时在每张图里面都都对应了3条曲线,也即add_scalars方法里的tag_scalar_dict参数;并且掌柜这里一共用了2个标签来进行分隔,即scalars1和scalars2。可视化的结果如图10所示。
3.4 add_histogram方法
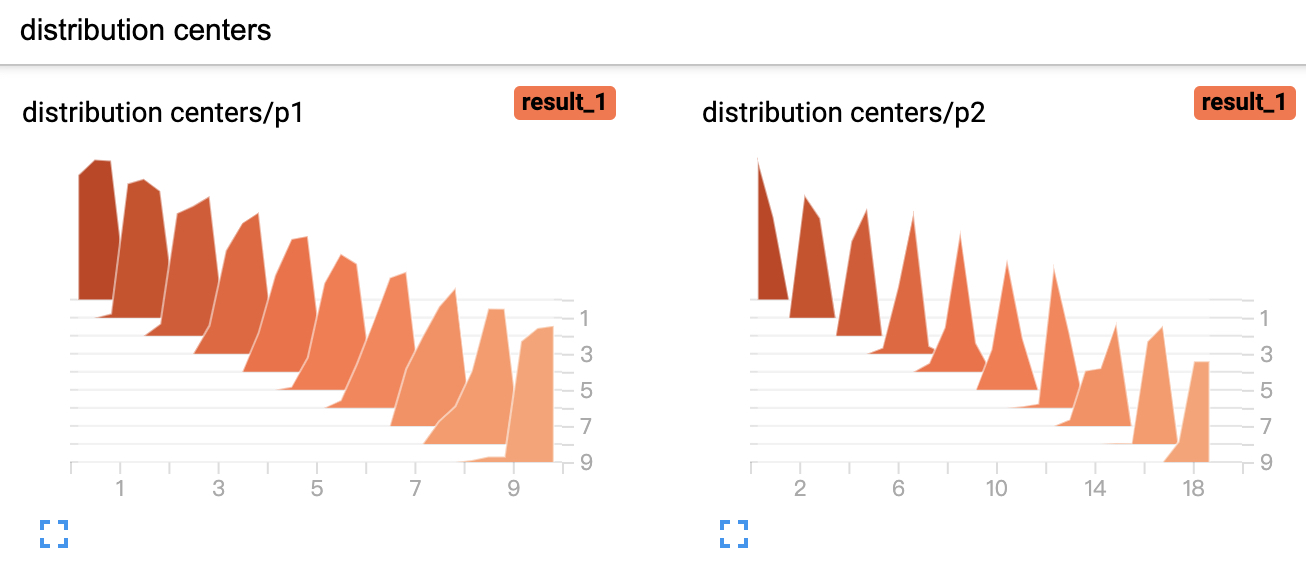
直方图的示例用法比较简单, 如下所示:
xxxxxxxxxx51def add_histogram(writer):2 for i in range(10):3 x = np.random.random(1000)4 writer.add_histogram('distribution centers/p1', x + i, i)5 writer.add_histogram('distribution centers/p2', x + i * 2, i)可视化后的结果如图11所示。
3.5 add_image方法
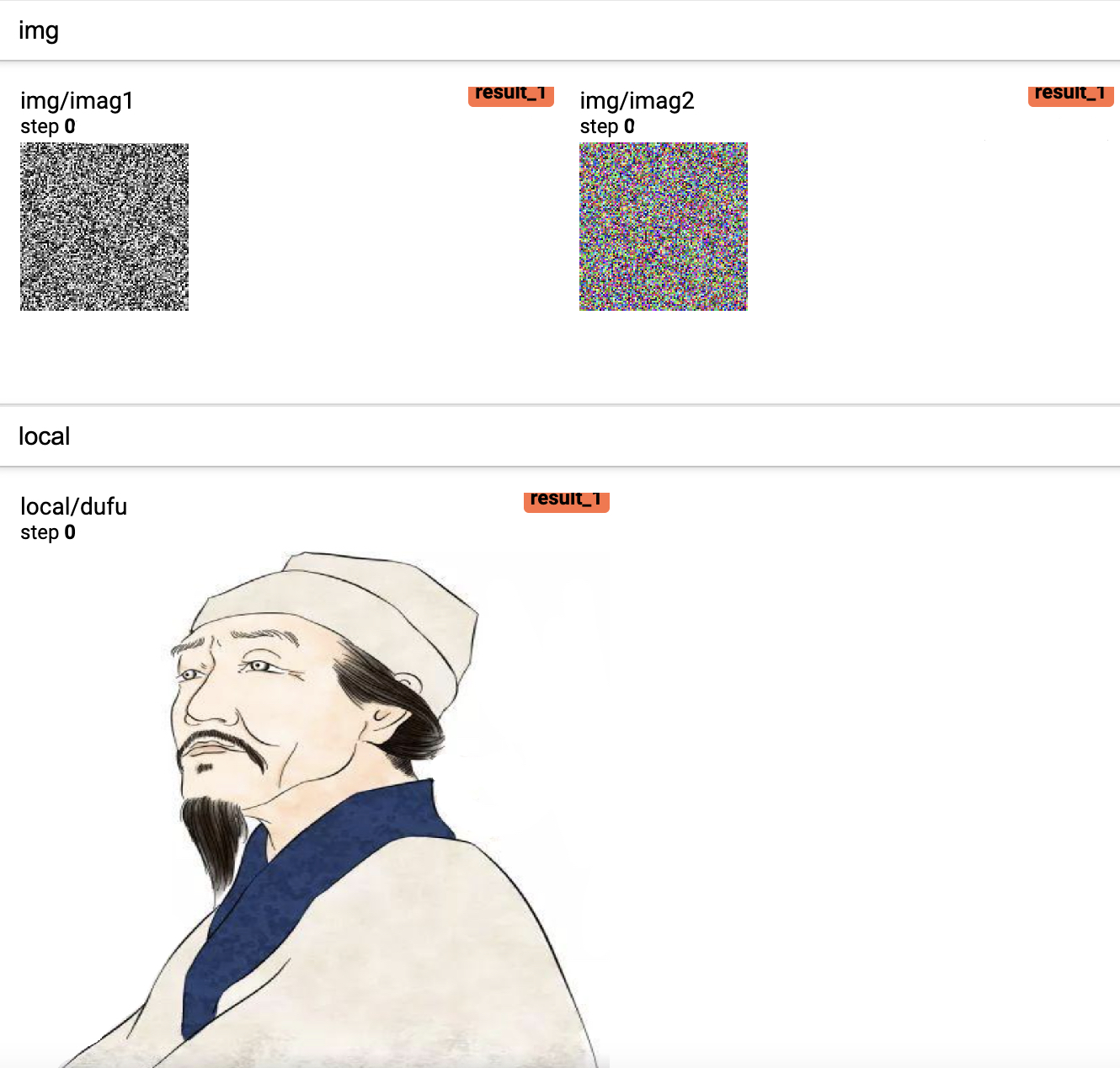
add_image方法是用来可视化相应的像素矩阵,例如本地图片,或者是特征图等
xxxxxxxxxx91def add_image(writer):2 from PIL import Image3 img1 = np.random.randn(1, 100, 100)4 writer.add_image('img/imag1', img1)5 img2 = np.random.randn(100, 100, 3)6 writer.add_image('img/imag2', img2, dataformats='HWC')7 img = Image.open('./dufu.png')8 img_array = np.array(img)9 writer.add_image('local/dufu', img_array, dataformats='HWC')在上述代码中,第3-4行用于生成一个形状为[C,H,W]的3维矩阵并进行可视化;第5-6行则是生成形状为[H,W,C]的3维矩阵并可视化,同时需要在add_image中指定矩阵的维度信息,因此可以看出add_image方法接受的默认格式为[C,H,W];第7-9行则是先从本地读取一张图片,然后再对其进行可视化,如图12所示。
3.6 add_images方法
从名字可以看出,该方法是一次性可视化多张像素图,使用示例如下:
xxxxxxxxxx81def add_images(writer):2 img1 = np.random.randn(8, 100, 100, 1)3 writer.add_images('imgs/imags1', img1, dataformats='NHWC')4 img2 = np.zeros((16, 3, 100, 100))5 for i in range(16):6 img2[i, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 / 16 * i7 img2[i, 1] = (1 - np.arange(0, 10000).reshape(100, 100) / 10000) / 16 * i8 writer.add_images('imgs/imags2', img2) # Default is :math:`(N, 3, H, W)`在上述代码中,第2-3行用于生成8张通道数为1的像素图并进行可视化;第4-8行则是生成16张通道数为3的像素图并进行可视化。最后可视化的结果如图13所示。

3.7 add_figure方法
这个方法的作用是用来将matplotlib包中的figure对象可视化到Tensoboard的网页端,用于展示一些较为复杂的图片,其示例用法如下:
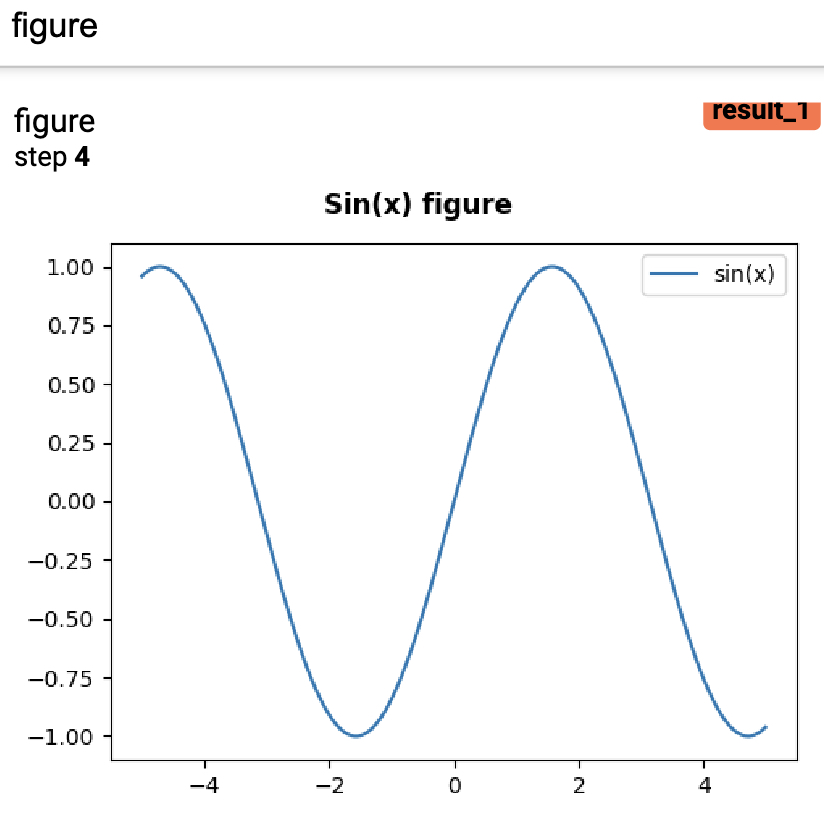
xxxxxxxxxx91def add_figure(writer):2 fig = plt.figure(figsize=(5, 4))3 ax = fig.add_axes([0.12, 0.1, 0.85, 0.8])4 xx = np.arange(-5, 5, 0.01)5 ax.plot(xx, np.sin(xx), label="sin(x)")6 ax.legend()7 fig.suptitle('Sin(x) figure\n\n', fontweight="bold")8 writer.add_figure("figure", fig, 4)9 # plt.show()在上述代码中,第2-7行为根据matplotlib包绘制相应的图像,其中第3行用来指定;第8行则是将其在Tensoboard中进行可视化;第9行则是直接在程序里进行可视化。最后可视化的结果如图14所示。
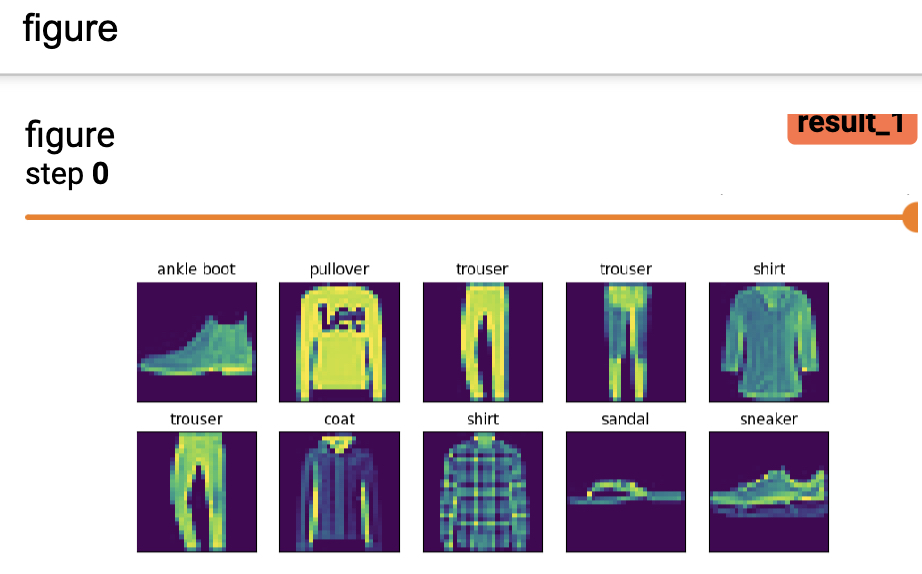
如果需要一次在Tensoboard中可视化一组图像的话,可以通过如下方式来进行实现:
xxxxxxxxxx111def add_figures(writer, images, labels):2 text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',3 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']4 labels = [text_labels[int(i)] for i in labels]5 fit, ax = plt.subplots(len(images) // 5, 5, figsize=(10, 2 * len(images) // 5))6 for i, axi in enumerate(ax.flat):7 image, label = images[i].reshape([28, 28]).numpy(), labels[i]8 axi.imshow(image)9 axi.set_title(label)10 axi.set(xticks=[], yticks=[])11 writer.add_figure("figure", fit)在上述代码中,掌柜选择是的FashionMNIST数据集进行的可视化;第5行代码用来生成一个包含有过个子图的画布;第6-10行是分别用来画出每一个子图;第10行用来去掉横纵坐标的信息;第11行则是将其在Tensoboard中进行展示。最终可视化后的结果如图15所示。
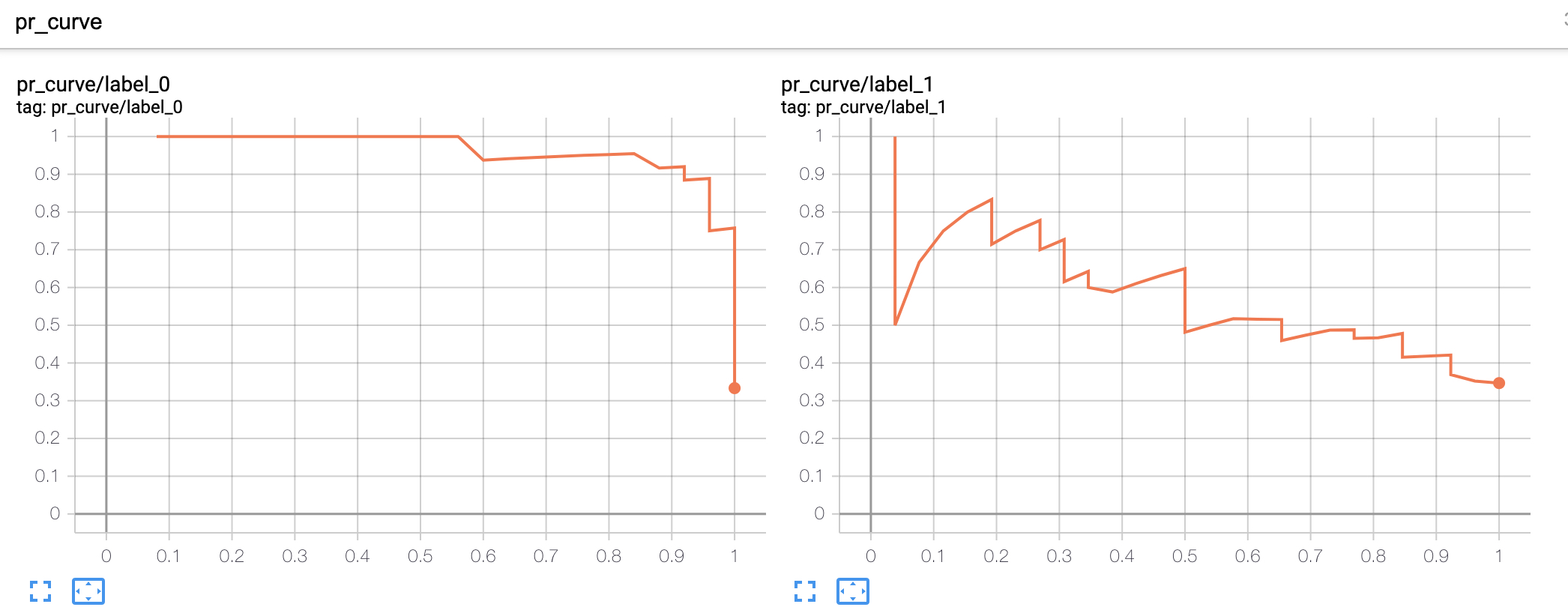
3.8 add_pr_curve方法
add_pr_curve这个方法是用来在训练过程中可视化Precision-Recall曲线,即观察在不同阈值下精确率与召回率的平衡情况。更多关于Precision-Recall曲线内容的介绍可以参考文章详解机器学习中的Precision-Recall曲线。用法示例如下所示:
xxxxxxxxxx231def add_pr_curve(writer):2 from sklearn.linear_model import LogisticRegression3 from sklearn.preprocessing import label_binarize4 def get_dataset():5 from sklearn.datasets import load_iris6 from sklearn.model_selection import train_test_split7 x, y = load_iris(return_X_y=True)8 random_state = np.random.RandomState(2020)9 n_samples, n_features = x.shape10 # 为数据增加噪音维度以便更好观察pr曲线11 x = np.concatenate([x, random_state.randn(n_samples, 100 * n_features)], axis=1)12 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.5,13 random_state=random_state)14 return x_train, x_test, y_train, y_test15
16 x_train, x_test, y_train, y_test = get_dataset()17 model = LogisticRegression(multi_class="ovr")18 model.fit(x_train, y_train)19 y_scores = model.predict_proba(x_test) # shape: (n,3)20
21 b_y = label_binarize(y_test, classes=[0, 1, 2]) # shape: (n,3)22 for i in range(3):23 writer.add_pr_curve(f"pr_curve/label_{i}", b_y[:, i], y_scores[:, i], global_step=1)在上述代码中,第2-19行代码用来根据逻辑回归生成预测结果,其中第11行用来给原始数据加入噪音,目的是为了可视化得到更加真实的PR曲线;第21行用来将原始标签转化为one-hot编码形式的标签;第22-23行则是分别根据每个类别的预测结果画出对应的PR曲线。运行上述代码将会得到类似如图16所示的结果。
3.9 add_embedding方法
这个方法作用是在三维空间中对高维向量进行可视化,默认情况下是对高维向量以PCA方法进行降维处理。add_embedding()方法主要有三个比较重要的参数mat、metadata和label_img,下面掌柜依次来进行介绍。
mat:用来指定可视化结果中每个点的坐标,形状为mat就是词向量矩阵,图片分类时mat可以是分类层的输出结果;
metadata:用来指定每个点对应的标签信息,是一个包含['1','2',....,'N'];
label_img:用来指定每个点对应可视化信息,形状为label_img就是每一张真实图片的可视化结果。
进一步,我们便可以通过如下代码来进行三维空间的高维向量可视化:
xxxxxxxxxx191def add_embedding(writer):2 import tensorflow as tf3 import tensorboard as tb4 tf.io.gfile = tb.compat.tensorflow_stub.io.gfile5 import keyword6 import torch7 # 随机生成100个标签信息8 meta = []9 while len(meta) < 100:10 meta = meta + keyword.kwlist # get some strings11 meta = meta[:100]12 for i, v in enumerate(meta):13 meta[i] = v + str(i)14 # 随机生成100个标签图片15 label_img = torch.rand(100, 3, 10, 32)16 for i in range(100):17 label_img[i] *= i / 100.018 data_points = torch.randn(100, 5) # 随机生成100个点19 writer.add_embedding(mat=data_points, metadata=meta, label_img=label_img, global_step=1)在上述代码中,第2-4行用于解决TensorFlow1.x版本的兼容性问题;第8-13行则是随机生成100个字符串标签信息;第15-17行则是生成标签对应的图片;第18行则是随机生成需要可视化的高维向量。上述代码运行结束后便会得到如图17所示的结果。
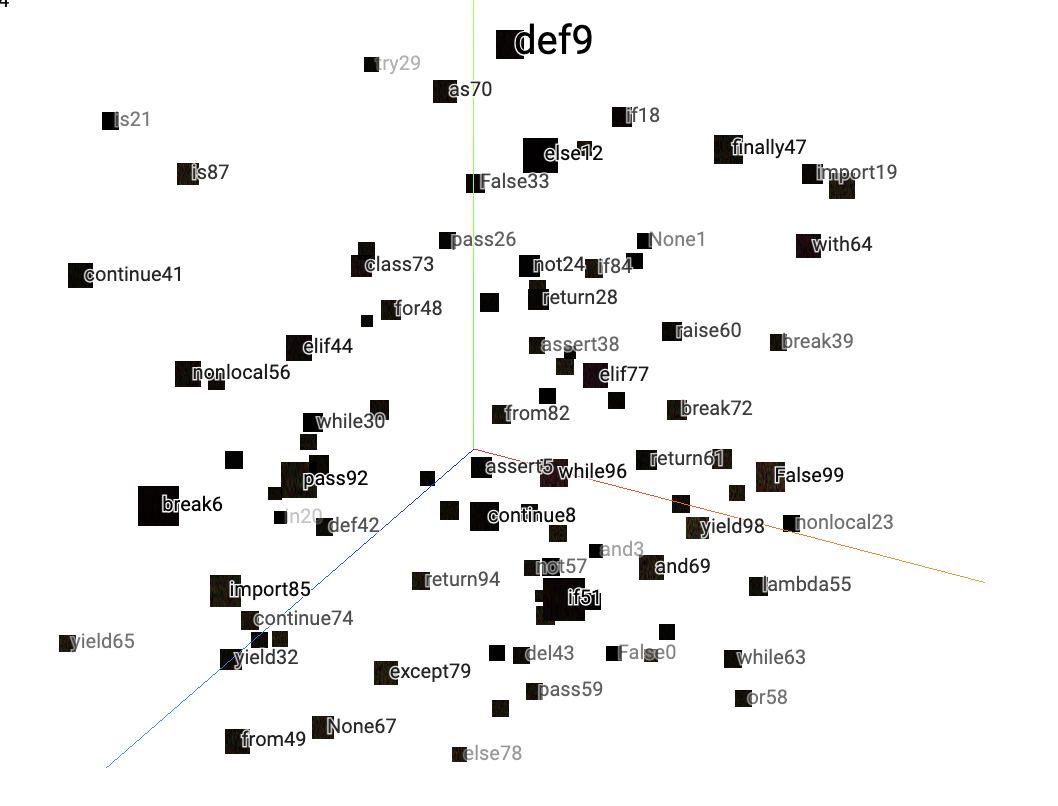
如图17所示,字符串就是上面代码中对应的metadata参数,黑色方块就是对应的label_img参数,而方块背后的点(图中看不到)就是对应的mat参数。这里掌柜只是用了随机数据生成了上面这张图,在下一节中掌柜将会用一个实际的例子来进行展示。
4 使用实例
4.1 定义模型
这里,掌柜以LeNet5网络模型进行示例,所以首先需要定义模型的前向传播过程,代码如下:
xxxxxxxxxx301import torch.nn as nn2
3class LeNet5(nn.Module):4 def __init__(self, ):5 super(LeNet5, self).__init__()6 self.conv = nn.Sequential( # [n,1,28,28]7 nn.Conv2d(1, 6, 5, padding=2), # in_channels, out_channels, kernel_size8 nn.ReLU(), # [n,6,24,24]9 nn.MaxPool2d(2, 2), # kernel_size, stride [n,6,14,14]10 nn.Conv2d(6, 16, 5), # [n,16,10,10]11 nn.ReLU(),12 nn.MaxPool2d(2, 2)) # [n,16,5,5]13
14 self.fc = nn.Sequential(15 nn.Flatten(),16 nn.Linear(16 * 5 * 5, 120),17 nn.ReLU(),18 nn.Linear(120, 84),19 nn.ReLU(),20 nn.Linear(84, 10))21
22 def forward(self, img, labels=None):23 output = self.conv(img)24 logits = self.fc(output)25 if labels is not None:26 loss_fct = nn.CrossEntropyLoss(reduction='mean')27 loss = loss_fct(logits, labels)28 return loss, logits29 else:30 return logits在上述代码中,第25-30行为根据不同的输入情况返回不同的结果。其余部的代码相对较为简单掌柜这里就不再赘述了,可以参考文章卷积池化与LeNet5网络模型。
4.2 定义分类模型
数据集构造
首先,我们需要构造训练模型时使用到的数据集,这里掌柜还是以FashionMNIST为例进行示例。构造代码如下所示:
xxxxxxxxxx151text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',2'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']34def load_dataset(batch_size=64):5mnist_train = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST',6train=True, download=True,7transform=transforms.ToTensor())8mnist_test = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST',9train=False, download=True,10transform=transforms.ToTensor())11train_iter = torch.utils.data.DataLoader(mnist_train,batch_size=batch_size,12shuffle=True,num_workers=1)13test_iter = torch.utils.data.DataLoader(mnist_test,batch_size=batch_size,14shuffle=True,num_workers=1)15return train_iter, test_iter在上述代码中,第1-2行为定义的每个标签序号所对应的标签名,用于在使用
add_embedding可视化预测结果时展示每个样本的标签名称;第5-15行则是分别构造训练集和测试集的DataLoader对象。定义分类模型
进一步,我们需要定义一个类来实现模型的整个训练和推理过程。首先定义这个类的初始化方法,代码如下:
xxxxxxxxxx111class MyModel:2def __init__(self,3batch_size=64,4epochs=3,5learning_rate=0.01):6self.batch_size = batch_size7self.epochs = epochs8self.learning_rate = learning_rate9self.model_save_path = 'model.pt'10self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')11self.model = LeNet5()定义评估方法
在这里,我们先定义一个评估函数,用来计算在测试集上模型的准确率。同时返回我们在使用Tensoboard可视化时需要用到的相关变量,代码如下:
xxxxxxxxxx1912def evaluate(data_iter, net, device):3net.eval()4all_logits = []5y_labels = []6images = []7with torch.no_grad():8acc_sum, n = 0.0, 09for x, y in data_iter:10x, y = x.to(device), y.to(device)11logits = net(x)12acc_sum += (logits.argmax(1) == y).float().sum().item()13n += len(y)14all_logits.append(logits)15y_pred = logits.argmax(1).view(-1)16y_labels += (text_labels[i] for i in y_pred)17images.append(x)18net.train()19return acc_sum / n, torch.cat(all_logits, dim=0), y_labels, torch.cat(images, dim=0)在上述代码中,第1行表示将这个方法声明为静态方法,因为函数里面没有使用到相关类成员;第4-6行分别定义了三个列表用于保存所有样本的预测logits向量、标签文本和原始表示;第10-13行用来累计预测正确样本的个数;第14-17分别用来处理得到在使用
add_embedding时所需要用到的变量;第19行则是返回所有需要用到的结果。定义训练过程
在完成上述步骤后便可以来实现模型训练部分的代码,同时对需要可视化的变量进行记录。由于这部分代码较长,掌柜就分块进行介绍。
xxxxxxxxxx141def train(self):2train_iter, test_iter = load_dataset(self.batch_size)3last_epoch = -14if os.path.exists('./model.pt'):5checkpoint = torch.load('./model.pt')6last_epoch = checkpoint['last_epoch']7self.model.load_state_dict(checkpoint['model_state_dict'])89num_training_steps = len(train_iter) * self.epochs10optimizer = torch.optim.Adam([{"params": self.model.parameters(),11"initial_lr": self.learning_rate}])12scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=300,13num_training_steps=num_training_steps,14num_cycles=2, last_epoch=last_epoch)在上述代码中,第4-7行用来判断本地是否存在之前保存的模型,如果存在则直接载入,而
last_epoch是用来获取得到之前模型结束训练时的状态,目的是能够使得Tensoboard在可视化的时候能够接着之前的数据集进行可视化(详情可以参见文章Transformers之自定义学习率动态调整第4节内容;第10-14行则是用来分别定义优化器和学习率动态调整策略。进一步,实现模型的训练步骤可损失、准确率和学习率的可视化过程,代码如下:
xxxxxxxxxx181writer = SummaryWriter("runs/nin")2max_test_acc = 03for epoch in range(self.epochs):4for i, (x, y) in enumerate(train_iter):5x, y = x.to(self.device), y.to(self.device)6loss, logits = self.model(x, y)7optimizer.zero_grad()8loss.backward()9optimizer.step() # 执行梯度下降10scheduler.step()11if i % 50 == 0:12acc = (logits.argmax(1) == y).float().mean()13print("### Epochs [{}/{}]---batch[{}/{}]---acc {:.4}---loss {:.4}".format(14epoch + 1, self.epochs, i, len(train_iter), acc, loss.item()))15writer.add_scalar('Training/Accuracy', acc, scheduler.last_epoch)16writer.add_scalar('Training/Loss', loss.item(), scheduler.last_epoch)17writer.add_scalar('Training/Learning Rate',18scheduler.get_last_lr()[0], scheduler.last_epoch)在上述代码中,第1行用来实例化
SummaryWriter用于后续可视化操作;第5-14行则是用来执行整个模型的训练过程;第15-18行则是用来分别对训练集上的准确率、损失和学习率进行可视化。最后一步便是通过
add_embedding来对预测结果进行可视化,代码如下:xxxxxxxxxx71test_acc, all_logits, y_labels, label_img = self.evaluate(test_iter,2self.model, self.device)3writer.add_scalar('Testing/Accuracy', test_acc, scheduler.last_epoch)4writer.add_embedding(mat=all_logits, # 所有点5metadata=y_labels, # 标签名称6label_img=label_img, # 标签图片7global_step=scheduler.last_epoch)在上述代码中,第1-2行主要用来获取
add_embedding所需要的遍历;第3-7行则是分别对测试集上的准确率和预测结果进行可视化。
4.3 可视化展示
在完成所有部分的编码工作后,便可以通过如下代码来运行整个模型:
xxxxxxxxxx31if __name__ == '__main__':2 model = MyModel()3 model.train()在程序运行开始后,便可以通过第3.1节中的方式启动Tensoboard前端界面,并可以看到如下图所示的可视化结果。
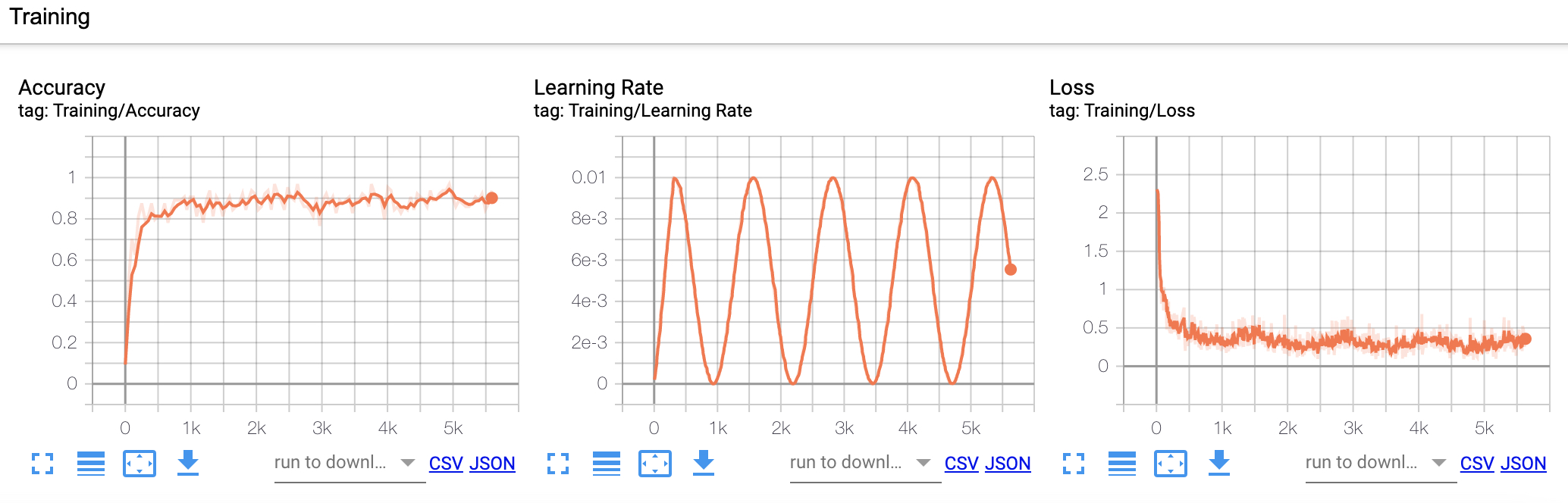
如图18所示便是模型在训练过程中在训练集上的准确率、学习率和损失的变化结果。
如图19所示便是模型在测试集上的预测结果经过add_embedding方法可视化后的结果,其中每个小方块都表示一个原始样本,每种颜色代表一个类别。进一步,点击任意方块便可以查看该样本的相关信息,如图20所示。
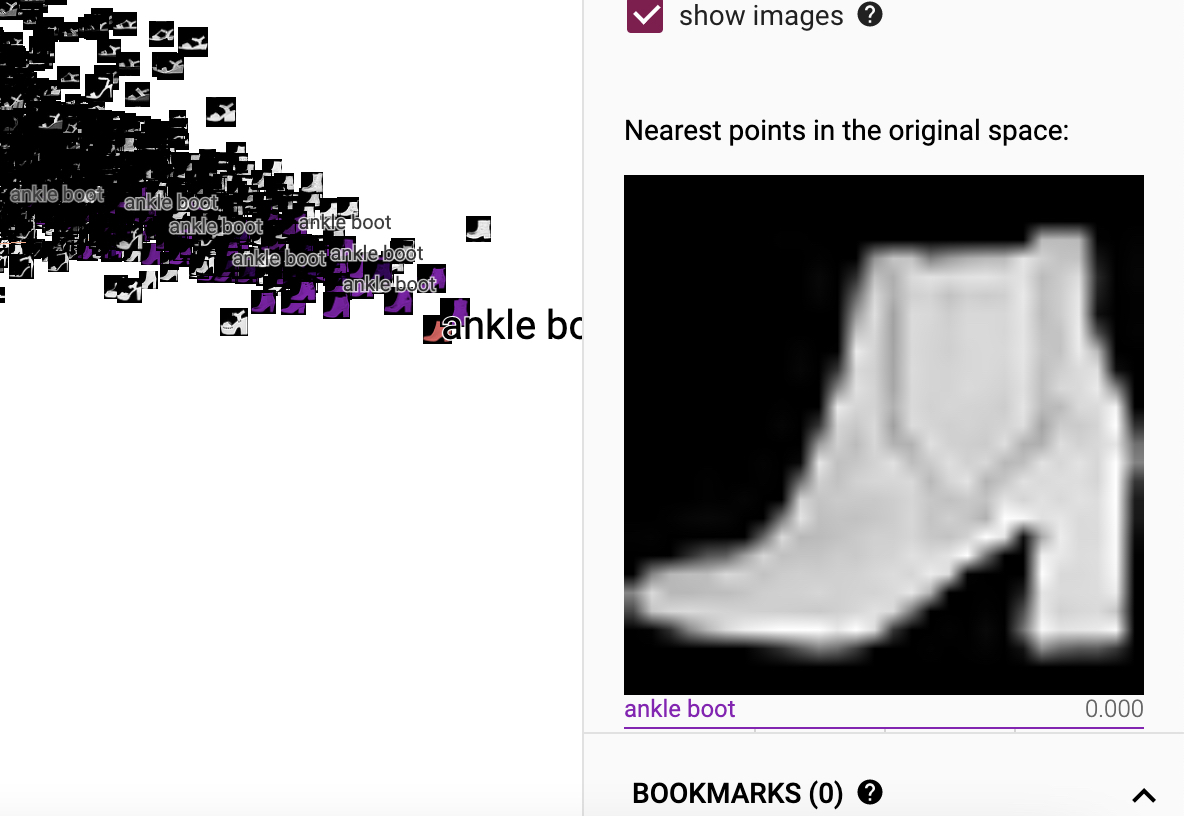
如图20所示便是ankle boot的可视化结果,并且可以发现只要点击其中一个样本,与它类别相同的样本也会被标记出来。当然,该页面还有其它相应的功能大家可以试着去探索,这里掌柜就不进行介绍了。
5 总结
在这篇文章中,掌柜首先详细介绍了如何在PyTorch框架下安装及启动Tensoboard,包括远程连接和本地连接两种方式;然后详细介绍了Tensoboard中常用的9中可视化函数的使用方法及示例;最后以一个实际的LeNet5分类模型来展示了相关可视化函数的使用方法。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎点赞分享!若有任何疑问与建议,请添加掌柜微信nulls8(备注来源)或文末留言进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1] 示例代码 https://github.com/moon-hotel/DeepLearningWithMe
[2] https://pytorch.org/docs/master/tensorboard.html#torch-utils-tensorboard


