1 引言
各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
经过前面一系列文章的介绍我们总算是对于Transformer有了清晰的认知。不过说起Transformer模型,其实在它发表之初并没有引起太大的反响,直到它的后继者BERT[1]的出现才使得大家再次回过头来仔细研究Transformer。因此,在接下来这个系列的文章中,掌柜将主要从BERT的基本原理、BERT模型的实现、BERT预训练模型在下游任务中的运用、Mask LM和NSP的实现与运用这几个方面来详细介绍Bert。总的来说就是先介绍如何在下游任务中运用预训练的BERT模型,然后再介绍如何利用Mask LM和NSP这两个任务来训练BERT模型。
关于Bert所取得的成就这里就不再细说,用论文里面作者的描述来说就是:BERT不仅在概念上很简单,并且从经验上来看它也非常强大,以至于直接刷新了11项NLP记录。
BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art re- sults on eleven natural language processing tasks.
作者之所以说BERT在概念上很简单,掌柜猜测这是因为BERT本质上是根据Transformer中Encoder堆叠而来所以说它简单;而作者说BERT从经验上来看非常强大,是因为BERT在训练过程中所基于的Mask LM和NSP这两个任务所以说其强大。
由于BERT是基于多层的Transformer堆叠而来,因此在整篇论文中关于BERT网络结构的细节之处作者并没有提及。同时,由于论文配了一张极具迷惑性的网络结构图,使得在不看源码的基础上你几乎很难弄清整个网络结构的细节之处。
BERT’s model architec- ture is a multi-layer bidirectional Transformer en- coder based on the original implementation de- scribed in Vaswani et al. (2017) and released in the tensor2tensor library.
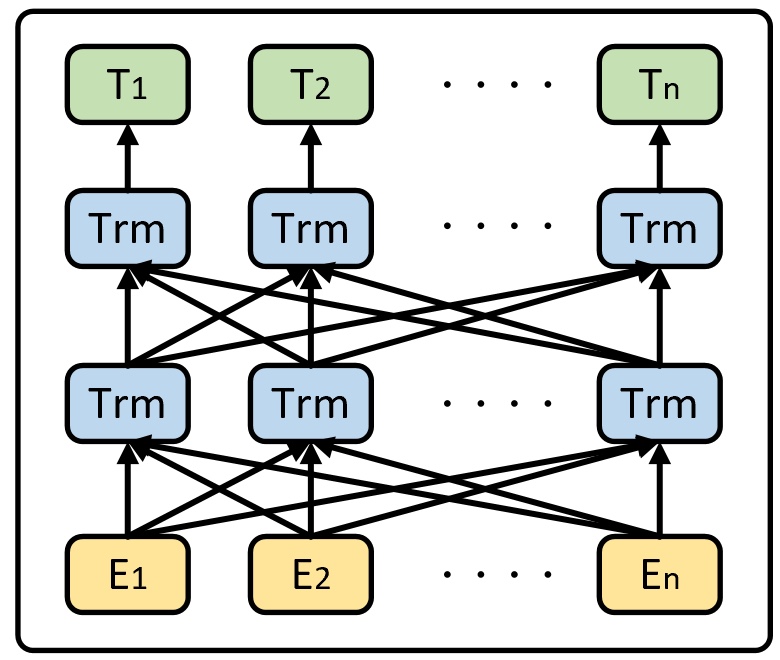
如图1所示就是论文中所展示的BERT网络结构图。看完论文后真的不知道作者为什么要画这么一个结构图,难道就是为了凸显“bidirectional ”?一眼看去,对于同一层的Trm来说它到底代表什么? 是类似于time step的展开,还是每个Trm都有着不同的权重?这些你都不清楚,当然论文也没有介绍。不过在看完这部分的源码实现后你就会发现,其实真正的BERT网络结构大体上应该是如图2所示的模样。
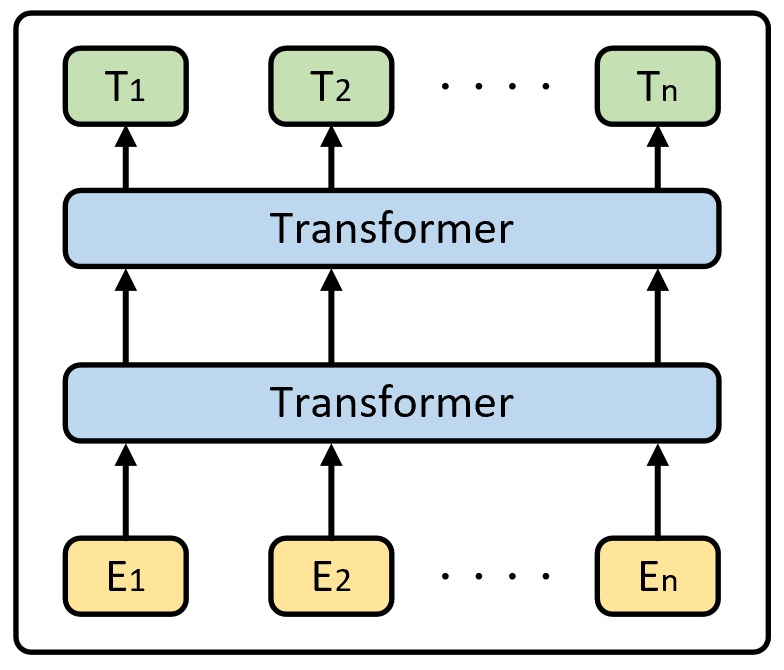
虽然从图2来看BERT的网络结构确实是不太复杂,但是其中的Transformer模块相较于原始Transformer[2]中的实现依旧有着不小的差别,不过这并不影响从整体上来认识BERT。
希望通过这一系列的篇文章能够让大家对BERT的原理与运用有一个比较清楚的认识与理解。下面,就让我们正式走进对于这篇论文的解读中来。公众号后台回复“论文”即可获得下载链接!
2 动机
2.1 面临问题
在论文的介绍部分作者谈到,预训练语言模型(Language model pre-training)对于下游很多自然语言处理任务都有着显著的改善。但是作者继续说到,现有预训练模型的网络结构限制了模型本身的表达能力,其中最主要的限制就是没有采用双向编码的方法来对输入进行编码。
Language model pre-training has been shown to be effective for improving many natural language processing tasks. We argue that current techniques restrict the power of the pre-trained representations, espe- cially for the fine-tuning approaches. The ma jor limitation is that standard language models are unidirectional.
例如在 OpenAI GPT中,它使用了从左到右(left-to-right)的网络架构,这就使得模型在编码过程中只能够看到当前只看之前的信息。
For example, in OpenAI GPT, the authors use a left-to- right architecture, where every token can only at- tend to previous tokens in the self-attention layers of the Transformer.

如图3所示,对于这句样本来说,无论是采用left-to-right还是right-to-left的方法,模型在对“it”进行编码时都不能够很好的捕捉到其具体的指代信息。这就像我们人在看这句话时一样,在没有看到“tired”这个词之前我们是无法判断“it”具体所指代的事物(例如把“tired”换成“wide”,则“it”指代的就是“street”)。如果采用双向编码的方式则从理论上来说就能够很好的避免这个问题,如图4所示。
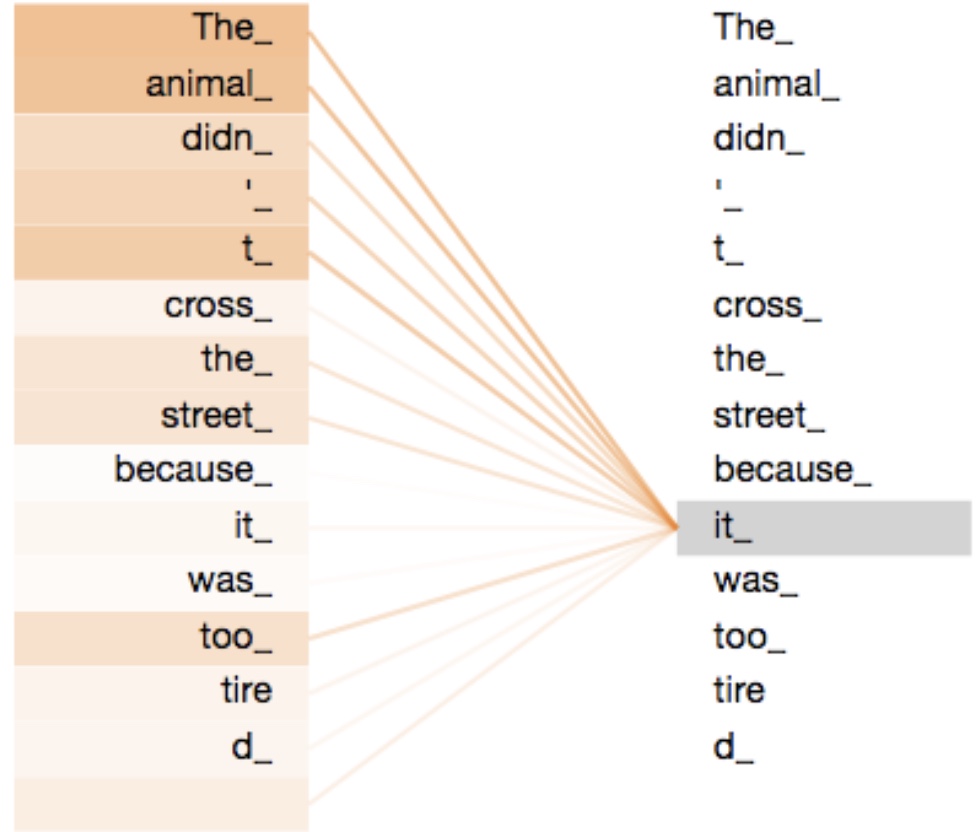
在图4中,橙色线条表示“it”应该将注意力集中在哪些位置上,颜色越深则表示注意力权重越大。通过这幅图可以发现,模型在对"it"进行编码时,将大部分注意力都集中在了”The animal“上,而这也符合我们预期的结果。
2.2 解决思路
在论文中,作者提出了采用BERT(Bidirectional Encoder Representations from Transformers)这一网络结构来实现模型的双向编码学习能力。同时,为了使得模型能够有效的学习到双向编码的能力,BERT在训练过程中使用了基于掩盖的语言模型(Masked Language Model, MLM),即随机对输入序列中的某些位置进行遮蔽,然后通过模型来对其进行预测。
In this paper, we improve the fine-tuning based approaches by proposing BERT: Bidirectional Encoder Representations from Transformers. BERT alleviates the previously mentioned unidi- rectionality constraint by using a “masked lan- guage model” (MLM) pre-training objective.
作者继续谈到,由于MLM预测任务能够使得模型编码得到的结果同时包含上下文的语境信息,因此有利于训练得到更深的BERT网络模型。除此之外,在训练BERT的过程中作者还加入了下句预测任务(Next Sentence Prediction, NSP),即同时输入两句话到模型中,然后预测第2句话是不是第1句话的下一句话。
3 技术实现
对于技术实现这部分内容,掌柜将会分为三个大的部分来进行介绍。第一部分主要介绍BERT的网络结构原理以及MLM和NSP这两种任务的具体原理;第二部分将主要介绍如何实现BERT以及BERT预训练模型在下游任务中的使用;第三部分则是介绍如何利用MLM和NSP这两个任务来训练BERT模型(可以是从头开始,也可以是基于开源的BERT预训练模型开始)。本篇文章将先对第一部分的内容进行介绍。
3.1 BERT网络结构
正如图2所示,BERT网络结构整体上就是由多层的Transformer Encoder堆叠所形成。关于Transformer部分的具体解读可以参见文章This post is all you need[4],这里就不再赘述。
BERT’s model architec- ture is a multi-layer bidirectional Transformer en- coder based on the original implementation de- scribed in Vaswani et al. (2017) [2].
当然,如果是将图2中的结果再细致化一点便能够得到如图5所示的网络结构图。
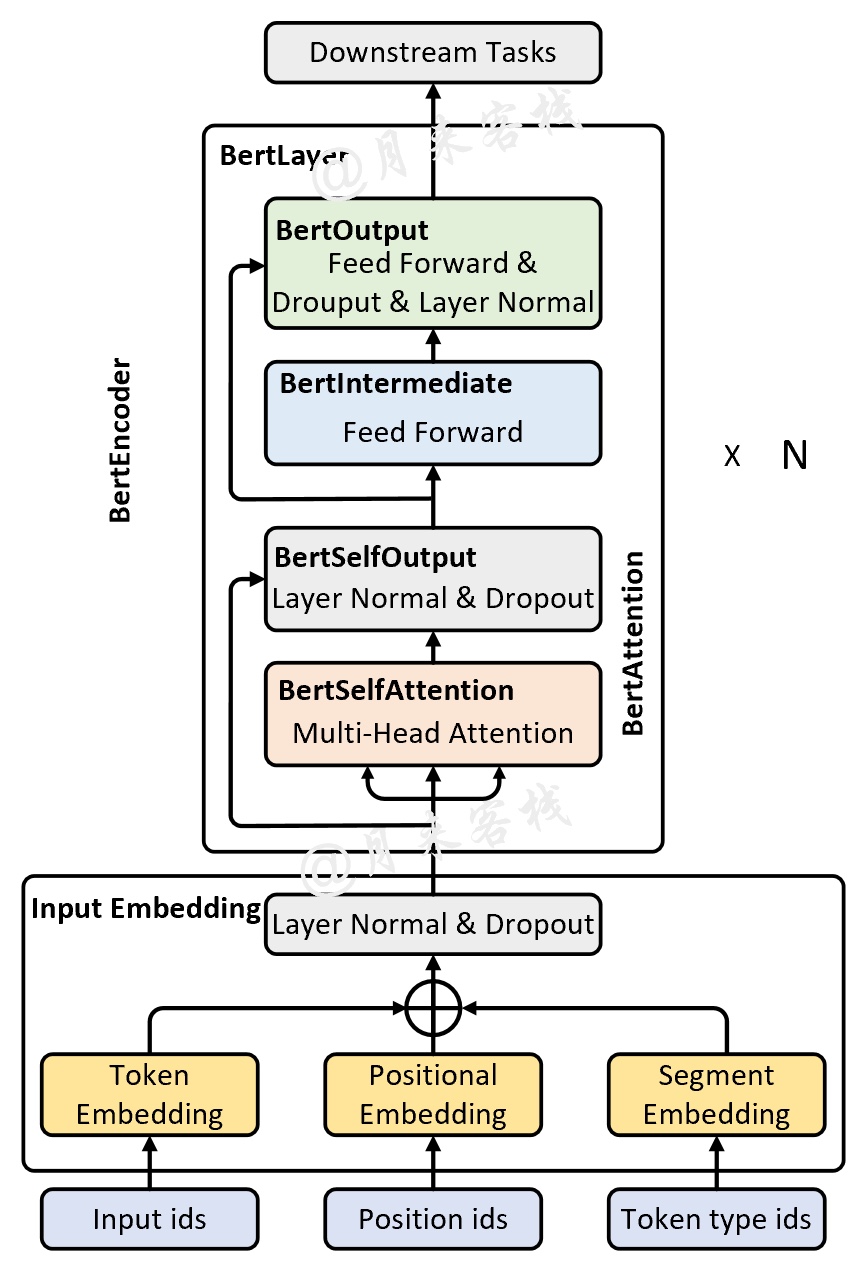
如图5所示便是一个详细版的BERT网络结构图,可以发现上半部分与之前的Transformer Encoder差不多,只不过在Input部分多了一个Segment Embedding。下面就开始分别对其中的各个部分进行介绍。
3.2 Input Embedding
如图6所示,在BERT中Input Embedding主要包含三个部分:Token Embedding、Positional Embedding和Segment Embedding。虽然前面两种Embedding在Transformer中已经介绍过,但是这里需要注意的是BERT中的Positional Embedding对于每个时刻的位置并不是采用公式计算出来的,其原理也是类似普通的词嵌入一样为每一个位置初始化了一个向量,然后随着网络一起训练。
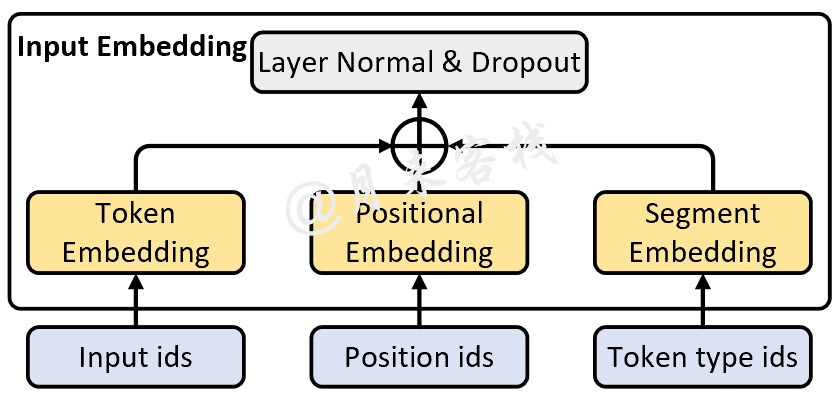
当然,最值得注意的一点就是BERT开源的预训练模型最大只支持512个字符的长度,这是因为其在训练过程中(位置)词表的最大长度只有512。
To speed up pretraing in our experiments, we pre-train the model with sequence length of 128 for 90% of the steps. Then, we train the rest 10% of the steps of sequence of 512 to learn the positional embeddings.
除此之外,第三部分则是BERT中引入的Segment Embedding。由于BERT的主要目的是构建一个通用的预训练模型,因此难免需要兼顾到各种NLP任务场景下的输入。因此Segment Embedding的作用便是便是用来区分输入序列中的不同序列,其本质就是通过一个普通的词嵌入来区分每一个序列所处的位置。例如在NSP任务中,那么对于任意一个序列的每一位置都将用同一个向量来进行表示,即此时Segment词表的长度为2。
最后,再将这三部分Embedding后的结果相加(并进行标准化)便得到了最终的Input Embedding部分的输出,如图7所示。
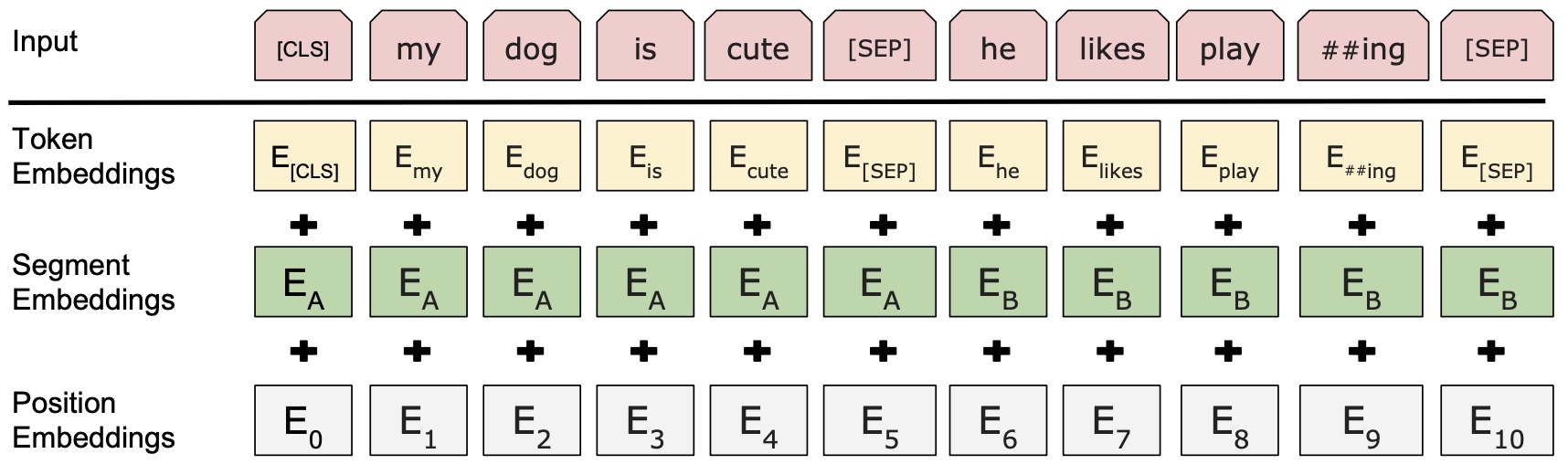
如图7所示,最上面的Input表示原始的输入序列,其中第一个字符”[CLS]“是一个特殊的分类标志,如果下游任务是做文本分类的话,那么在BERT的输出结果中可以只取"[CLS]"对应的向量进行分类即可;而其中的"[SEP]"字符则是用来作为将两句话分开的标志。Segment Embedding层则同样是用来区分两句话所在的不同位置,对于每句话来说其内部各自的位置都是一样的,当然如果原始输入就只有一句话,那么Segment Embedding层中对应的每个Token的位置向量都是一样的。最后,Positional Embedding则是用来标识句子中每个Token各自所在的位置,使得模型能够捕捉到文本”有序“这一特性。具体细节之处见后续代码实现。
Sentence pairs are packed together into a single sequence. We differentiate the sentences in two ways. First, we separate them with a special token ([SEP]). Second, we add a learned embed- ding to every token indicating whether it belongs to sentence A or sentence B.
3.3 BertEncoder
如图8所示便是Bert Encoder的结构示意图,其整体由多个BertLayer(也就是论文中所指代的Transformer blocks)所构成。
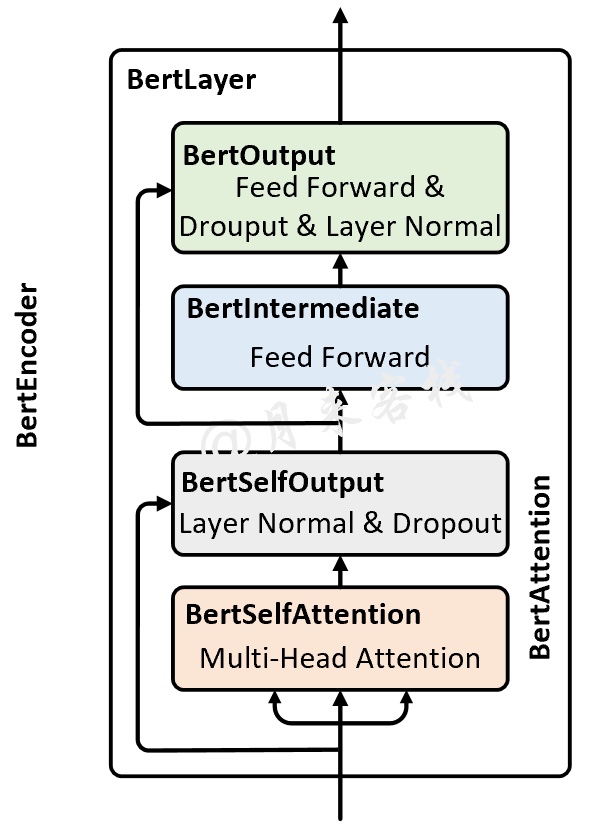
具体的,在论文中作者分别用来表示BertLayer的层数,即BertEncoder是由个BertLayer所构成;用来表示模型的维度;用来表示多头注意力中多头的个数。同时,在论文中作者分别就和这两种尺寸的BERT模型进行了实验对比。由于这部分类似的内容在Transformer中已经进行了详细介绍,所以这里就不再赘述,细节之处见后续代码实现。
3.4 MLM与NSP
为了能够更好训练BERT网络,论文作者在BERT的训练过程中引入两个任务,MLM和NSP。对于MLM任务来说,其做法是随机掩盖掉输入序列中的Token(即用"[MASK]"替换掉原有的Token),然后在BERT的输出结果中取对应掩盖位置上的向量进行真实值预测。
In order to train a deep bidirectional representation, we simply mask some percentage of the input tokens at random, and then predict those masked tokens. In this case, the final hidden vectors corresponding to the mask tokens are fed into an output softmax over the vocabulary, as in a standard LM. In all of our experiments, we mask 15% of all WordPiece tokens in each sequence at random.
接着作者提到,虽然MLM的这种做法能够得到一个很好的预训练模型,但是仍旧存在不足之处。由于在fine-tuning时,输入序列中并不存在”[MASK]“这样的Token,因此这将导致pre-training和fine-tuning之间存在不匹配的问题。
Although this allows us to obtain a bidirec- tional pre-trained model, a downside is that we are creating a mismatch between pre-training and fine-tuning, since the [MASK] token does not ap- pear during fine-tuning.
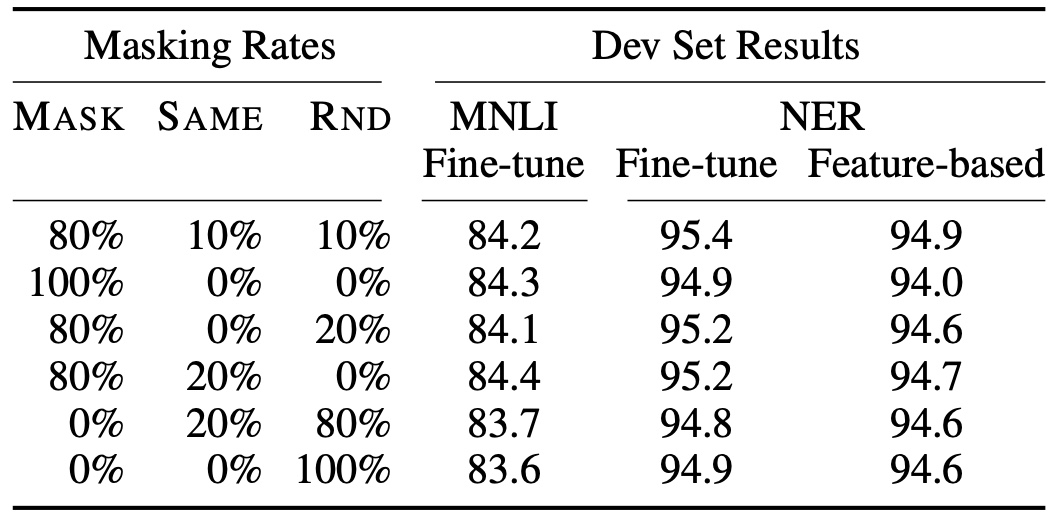
为了解决这一问题,作者在原始MLM的基础了做了部分改动,即先选定的Token,然后将其中的替换为"[MASK]"、随机替换为其它Token、剩下的不变。最后取这的Token对应的输出做分类来预测其真实值。
The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time.
最后,作者还给出了一个不同掩盖策略下的对比结果,如图9所示。
由于很多下游任务需要依赖于分析两句话之间的关系来进行建模,例如问题回答等。为了使得模型能够具备有这样的能力,作者在论文中又提出了二分类的下句预测任务。
Many important downstream tasks such as Ques- tion Answering (QA) and Natural Language Infer- ence (NLI) are based on understanding the rela- tionship between two sentences. In order to train a model that understands sentence relationships, we pre-train for a binarized next sen- tence prediction task.
具体地,对于每个样本来说都是由A和B两句话构成,其中的情况B确实为A的下一句话(标签为IsNext),另外的的情况是B为语料中其它的随机句子(标签为NotNext),然后模型来预测B是否为A的下一句话。
Specifically, when choosing the sentences A and B for each pretraining example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext).
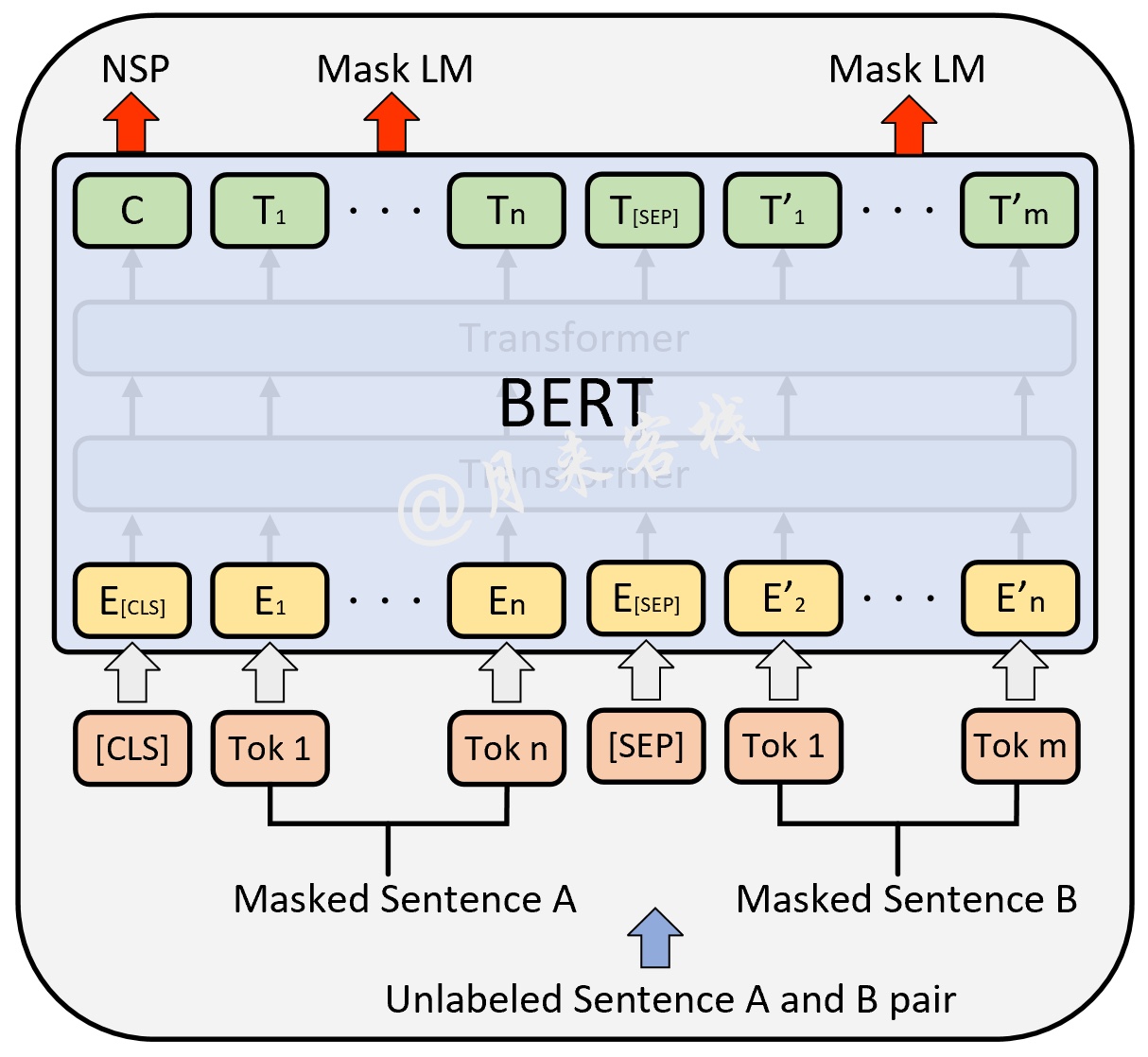
如图10所示便是ML和NSP这两个任务在BERT预训练时的输入输出示意图,其中最上层输出的在预训练时用于NSP中的分类任务;其它位置上的则用于预测被掩盖的Token。
到此,对于BERT模型的原理以及NSP、MLM这两个任务的内容就介绍完了。
4 总结
对于BERT来说,如果单从网络结构上来说的话,个人感觉并没有太大的创新,这也正如作者所说”BERT整体上就是由多层的Transformer Encoder堆叠所形成“,并且所谓的”Bidirectional“其实指的也就是Transformer中的self-attention机制。真正让BERT表现出色的应该是基于MLM和NSP这两种任务的预训练过程,使得训练得到的模型具有强大的表征能力。在下一篇文章中,掌柜将会详细介绍如何动手来实现BERT模型,以及如何载入现有的模型参数并运用在下游任务中。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎分享至一位你的朋友!若有任何疑问与建议,请添加掌柜微信'nulls8'或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
[2]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need
[3]http://jalammar.github.io/illustrated-transformer/
[4]This post is all you need
[5]The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) https://jalammar.github.io/illustrated-bert/


