1 引言
各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
在前面的文章中掌柜虽然已经详细地介绍了朴素贝叶斯算法的基本思想与原理,但对于具体的实现细节掌柜并没有过多的介绍。在这篇文章中,掌柜将会从零开始一步一步地来介绍如何实现朴素贝叶斯(估计)模型,以便让大家对于朴素贝叶斯算法有着更加清晰的认识。
2 朴素贝叶斯原理
在正式介绍朴素贝叶斯的代码实现之前,掌柜先带着大家简单地来回顾一下算法求解步骤与计算过程;然后再根据计算过程的顺序来一步一步实现整个模型。对于朴素贝叶斯的详细原理可以参加文章朴素贝叶斯算法。
2.1 求解步骤
根据前面文章的介绍,可以将朴素贝叶斯分类算法的求解步骤总结如下:
输入:训练数据
输出:实例
1) 计算先验概率与条件概率
根据极大似然估计,用给定的数据集来计算各类别的先验概率和条件概率。
其中
2) 计算各特征取值下的后验概率
3) 极大化后验概率确定类别
最后,只需要选择对应后验概率值最大的类别作为该样本的预测类别即可。
2.2 计算示例
在简单介绍完朴素贝叶斯的计算过程后,下面再来通过一个实际的计算示例来体会一下朴素贝叶斯分类器的计算流程。
如表1所示为一个信用卡审批数据集,其中
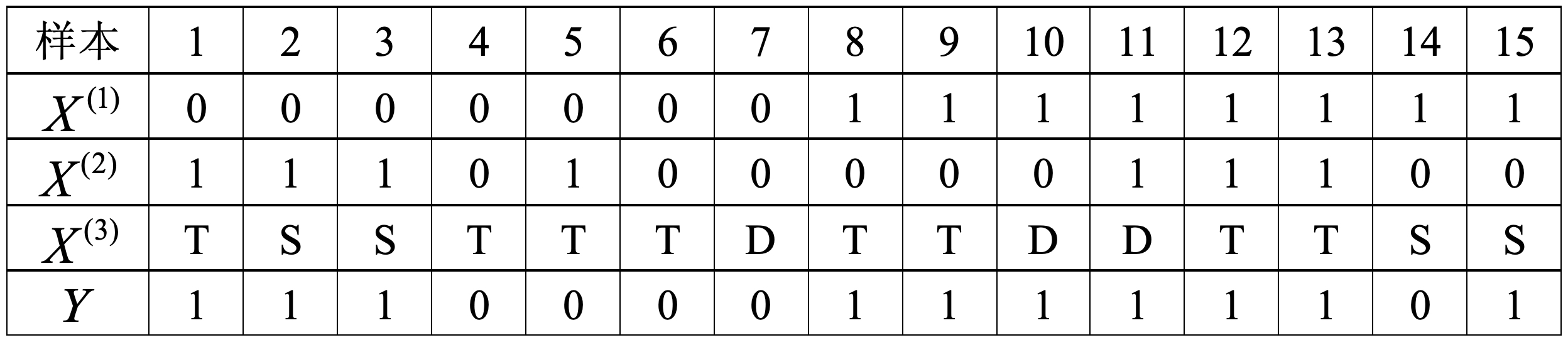
根据式
各类别下不同特征取值的条件概率为
以上计算过程便是根据训练集训练朴素贝叶斯分类器模型参数的过程。根据这些参数,便可以对给定的
首先根据式
于是便可以知道,样本
3 朴素贝叶斯实现
在回顾完朴素贝叶斯的相关基本原理后,接下来掌柜就开始分步对各个部分的实现进行介绍。同时,需要说明的是以下实现代码均参考自sklearn 0.24.0 中的CategoricalNB模块,只是对部分处理逻辑进行了修改与简化。
3.1 特征计数实现
通过第2节的内容可知,不管是计算先验概率还是条件概率,在这之前都需要先统计训练集中各个样本及样本特征取值的分布情况。因此,这里首先需要初始化相关的计数器;然后再对样本和特征样本特征取值的分布情况进行统计。
如下代码所示便是对两个重要计数器初始化工作:
xxxxxxxxxx91class MyBayes(object):2
3 def __init__(self, alpha=1.0):4 self.alpha = alpha5
6 def _init_counters(self):7 self.class_count_ = np.zeros(self.n_classes, dtype=np.float64)8 self.category_count_ = [np.zeros((self.n_classes, 0))9 for _ in range(self.n_features_)]在上述代码中,第3-4行是初始化平滑项系数alpha。第7行class_count_被初始化成了一个形状为[n_classes,]的全零向量,其中n_classes表示分类的类别数量,而每个维度分别表示每个类别的样本数量(例如[2,2,3]表示0,1,2这三个类别的样本数分别是2,2,3),其目的是后续用于计算每个类别的先验概率。第8行category_count_被初始化成了一个包含有n_features_个元素的列表,其中n_features_表示数据集的特征维度数量,同时category_count_中每个元素的形状是[n_classes,0](后续每个元素将会更新为[n_classes,len(X_i)]的形状,len(X_i)表示X_i这个特征的取值情况数量);而category_count_的作用是记录在各个类别下每个特征变量中各种取值情况的数量,例如category_count_[i][j][k]为10表示含义就是特征i在类别j下特征取值为k的样本数量为10个。
在初始化两个计数器之后,进一步便可以实现各个类别及特征分布的统计,代码如下:
xxxxxxxxxx171 def _count(self, X, Y):2 def _update_cat_count(X_feature, Y, cat_count, n_classes):3 for j in range(n_classes): # 遍历每个类别4 mask = Y[:, j].astype(bool) # 取每个类别下对应样本的索引5 counts = np.bincount(X_feature[mask]) # 统计当前类别下,特征X_feature中各个取值下的数量6 indices = np.nonzero(counts)[0]7 cat_count[j, indices] += counts[indices]8 9 self.class_count_ += Y.sum(axis=0) # Y: shape(n,n_classes) Y.sum(): shape(n_classes,)10 self.n_categories_ = X.max(axis=0) + 111
12 for i in range(self.n_features_): # 遍历每个特征13 X_feature = X[:, i] # 取每一列的特征14 self.category_count_[i] = np.pad(self.category_count_[i],15 [(0, 0), (0, self.n_categories_[i])],16 'constant') 17 _update_cat_count(X_feature, Y,self.category_count_[i],self.n_classes)在上述代码中,第1行参数Y是原始标签经过one-hot编码后的形式,例如3分类问题中类别1会被编码成[0,1,0]的形式,因此Y的形状为[n,n_classes];第9行代码是计算得到每个类别对应的样本数量;第10行则是统计每个特征维度的取值数量(因为特征取值是从0开始的所以后面加了1),例如[3 3 3 3]表示四个特征维度的取值均有3种情况;第12-13行开始遍历每个特征并取对应的特征列;第14-16行是对category_count_中的每个元素填充self.n_categories_[i]列全0向量,此时category_count_中每个元素将会变成形状为[n_classes,len(X_i)]的全零矩阵;第17行则是根据输入的每一列特征等相关参数来更新category_count_计数器。
第3-5行为遍历每一个样本类别,并取每个类别下对应样本的索引,同时统计当前类别下特征列X_feature中各个取值下的数量。同时,第5行中np.bincount的作用的是统计每个值出现的次数,例如:
xxxxxxxxxx41counts = np.bincount(np.array([0, 3, 5, 1, 4, 4]))2print(counts) 3# [1 1 0 1 2 1]4表示[0, 3, 5, 1, 4, 4]中0,1,2,3,4,5这个6个值的出现的频次分别是1,1,0,1,2,1第6-7行则是用来更新cat_count中当前输入特征每种取值情况的分布数量,例如cat_count[i,k]表示的是第i个类别下,特征X_feature的第k个取值的数量。
例如对于表1中的数据集来说,其对应的category_count_计数器的结果为:
xxxxxxxxxx31 [array([[4., 1.],[3., 7.]]), 2 array([[4., 1.],[4., 6.]]), 3 array([[1., 1., 3.],[2., 3., 5.]])]其中[[4., 1.],[3., 7.]]分别表示的含义就是:对于第1个特征y=0这个类别下,y=1这个类别下,
同理,对于第2个特征y=0这个类别下,y=1这个类别下,
到此,对于数据集中样本及特征分布情况的计数就算是统计完了,接下来开始先验概率和条件概率。
3.2 先验概率实现
有了数据集中各个样本的分布情况后,计算先验概率就变得十分简单了,代码如下:
xxxxxxxxxx31 def _update_class_prior(self):2 self.class_prior_ = (self.class_count_ + self.alpha) / # shape: [n_classes, ] 3 (self.class_count_.sum() + self.n_classes * self.alpha)在上述代码中,第2-3便是用来计算各个类别的先验概率,其中带有alpha的地方为平滑处理项。值得一提的是在sklearn中对于类别的先验概率并没有采取平滑处理(等价于第2-3行中alpha=0时的情况),这是因为数据集中也不可能出现整个类别缺失的情况。这里加上平滑处理只是为了与之前介绍的内容相匹配。
3.3 条件概率实现
进一步,可以根据category_count_中的统计结果来实现各特征取值的条件概率,代码如下:
xxxxxxxxxx101 def _update_feature_prob(self):2 feature_prob = []3 for i in range(self.n_features_): # 遍历 每一个特征4 smoothed_cat_count = self.category_count_[i] + self.alpha5 smoothed_class_count = self.category_count_[i].sum(axis=1) + 6 self.category_count_[i].shape[1] * self.alpha7 cond_prob = smoothed_cat_count / smoothed_class_count.reshape(-1, 1)8 feature_prob.append(cond_prob)9 self.feature_prob_ = feature_prob10 # feature_prob_ 为一个包含有n_features_个元素的列表,每个元素的shape为 (self.n_classes,特征取值数)在上述代码中,第4行是取当前特征在不同类别下各个特征的取值的统计结果,并加上平滑项系数;第5-6行是计算在当前特征下各类别样本的总数,并进行平滑处理;第7行则是计算每个特征取值对应的条件概率。
因此,feature_prob_[i][j][k]表示的就是特征i在类别j下取值为k时的概率。例如对于表1中的训练数据集来说,计算得到feature_prob_的结果如下所示:
xxxxxxxxxx21[[0.8 0.2] [[0.8 0.2] [[0.2 0.2 0.6] 2 [0.3 0.7]] [0.4 0.6]] [0.2 0.3 0.5]]上述结果中,第1个元素表示:对于第1个特征y=0这个类别下,y=1这个类别下,
3.4 模型拟合实现
上述先验概率和条件概率的计算对应便是整个模型的拟合过程,换句话说对于贝叶斯算法来说,所谓的模型拟合就是计算先验概率和条件概率。在实现这部分代码之后,再通过一个函数将整个过程串起来即可,代码如下:
xxxxxxxxxx131 def fit(self, X, y):2 self.n_features_ = X.shape[1]3 labelbin = LabelBinarizer() 4 Y = labelbin.fit_transform(y) 5 self.classes_ = labelbin.classes_ 6 if Y.shape[1] == 1: 7 Y = np.concatenate((1 - Y, Y), axis=1) 8 self.n_classes = Y.shape[1]9 self._init_counters() # 初始化计数器10 self._count(X, Y) # 对各个特征的取值情况进行计数,以计算条件概率等11 self._update_class_prior()12 self._update_feature_prob()13 return self在上述代码中,第2-4行用来将原始[0,1,2,3...]这样的标签转换为one-hot编码形式的标签值,形状为[n,n_classes];第5行用来记录原始的标签类别,形状为[n_classes,];第6-7行用来处理当数据集为二分类时fit_transform处理后的结果并不是one-hot形式,需要添加一列来转换成one-hot形式;第8行是获取数据集的类别数量;第9-12行则分别是上面3节内容介绍到的初始化计数器、特征取值分布情况统计、计算先验概率和计算条件概率。
3.5 后验概率实现
在完成模型的拟合过程后,对于新输入的样本来说其最终的预测结果则取决于对应的极大后验概率。实现代码如下所示:
xxxxxxxxxx131 def _joint_likelihood(self, X):2 if not X.shape[1] == self.n_features_:3 raise ValueError("Expected input with %d features, got %d instead"4 % (self.n_features_, X.shape[1]))5 jll = np.ones((X.shape[0], self.class_count_.shape[0])) # 用来累积条件概率6 for i in range(self.n_features_):7 indices = X[:, i] # 取对应的每一列特征8 if self.feature_prob_[i].shape[1] <= indices.max():9 raise IndexError(f"测试集中的第{i}个特征维度的取值情况"10 f" {indices.max()} 超出了训练集中该维度的取值情况!")11 jll *= self.feature_prob_[i][:, indices].T # 取每个特征取值下对应的条件概率,并进行累乘12 total_ll = jll * self.class_prior_ # 条件概率乘以先验概率即得到后验概率13 return total_ll在上述代码中,第2-4行用来判断输入样本的特征维度是否等于训练集中样本的特征维度;第5行是初始化每个样本的联合似然估计值;第6-7行是遍历测试数据中对应的每一列特征;第11行是取每个特征取值下对应类别的条件概率,并进行累乘(因为self.feature_prob_[i][:, indices]的形状为[n_classes,n],而jll的初始形状为[n,n_classes]所以前者要进行转置);第12行则是计算每个样本对应的后验概率估计。
同时值得注意的一点是,在文本向量化中对于考虑词频的词袋模型来说,其向量表示并不能直接使用于这里实现的贝叶斯模型。因为此时训练集词表中每个词出现的次数并不是该特征维度对应的取值情况数,而是表示的频次。例如在训练集中“客栈”这个词出现的最大次数为10,那么模型在拟合过程中就会认为“客栈”这个维度的特征取值有10种情况,并以此进行建模;但是当测试集中的某个样本里“客栈”这个词出现的频次为11时,那么模型便会认为该维度多了一种取值情况,进而无法取到对应的条件概率。所以掌柜在8-10行中加了对应的判断条件。
在实现完个样本后验概率的计算结果后,最后一步需要完成的便是极大化操作,即从所有后验概率中选择最大的概率值对应的类别作为该样本的预测类别即可。实现代码如下所示:
xxxxxxxxxx81 def predict(self, X, with_prob=False):2 from scipy.special import softmax3 jll = self._joint_likelihood(X)4 y_pred = self.classes_[np.argmax(jll, axis=1)]5 if with_prob:6 prob = softmax(jll)7 return y_pred, prob8 return y_pred在上述代码中,第4行便是极大化后验概率的操作;第5-8样则是根据对应的参数来返回预测后的结果。
3.6 使用示例
下面,掌柜先以表1中的模拟数据来通过上述实现的代码进行示例。
首先需要构建表1中的模拟数据,代码如下:
xxxxxxxxxx61def load_simple_data():2 x = np.array([[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],3 [1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0],4 [2, 1, 1, 2, 2, 2, 0, 2, 2, 0, 0, 2, 2, 1, 1]]).transpose()5 y = np.array([1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1])6 return x, y其中特征0,1,2来进行代替。
接着来实现模型的构建部分,代码如下:
xxxxxxxxxx181def test_naive_bayes():2 x, y = load_simple_data()3 logging.info(f"My Bayes 运行结果:")4 model = MyBayes(alpha=0)5 model.fit(x, y)6 logging.info(model.predict(np.array([[0, 1, 0]]), with_prob=True))7 logging.info(f"CategoricalNB 运行结果:")8 model = CategoricalNB(alpha=0)9 model.fit(x, y)10 logging.info(model.predict(np.array([[0, 1, 0]])))11 logging.info(model.predict_proba(np.array([[0, 1, 0]])))12if __name__ == '__main__':13 formatter = '[%(asctime)s] - %(levelname)s: %(message)s'14 logging.basicConfig(level=logging.DEBUG,15 format=formatter, 16 datefmt='%Y-%m-%d %H:%M:%S',17 handlers=[logging.StreamHandler(sys.stdout)])18 test_naive_bayes()在上述代码中,掌柜分别用了我们自己动手实现的贝叶斯模型和sklearn中的CategoricalNB模块进行对比;第13-17行为相关计算过程的日志打印输出,关于这部分内容可以参见文章训练模型时如何保存训练日志?。
最终,上述代码中的运行结果如下所示:
xxxxxxxxxx221[2022-03-12 10:09:52] - INFO: My Bayes 运行结果:2[2022-03-12 10:09:52] - DEBUG: 每个类别下的样本数class_count_(n_classes,): [ 5. 10.]3[2022-03-12 10:09:52] - DEBUG: 每个特征的取值种数n_categories_:[2 2 3]4[2022-03-12 10:09:52] - DEBUG: 各个特征每个取值的数量分布(未平滑处理) category_count_:5 [array([[4., 1.],[3., 7.]]), 6 array([[4., 1.],[4., 6.]]), 7 array([[1., 1., 3.],[2., 3., 5.]])]8[2022-03-12 10:09:52] - DEBUG: n_classes:29[2022-03-12 10:09:52] - DEBUG: class_count_:[ 5. 10.]10[2022-03-12 10:09:52] - DEBUG: 计算每个类别的先验概率class_prior_:[0.33333333 0.66666667]11[2022-03-12 10:09:52] - DEBUG: 第0个特征在各类别下各个特征取值的条件概率为: 12[[0.8 0.2],[0.3 0.7]]13[2022-03-12 10:09:52] - DEBUG: 第1个特征在各类别下各个特征取值的条件概率为: 14[[0.8 0.2],[0.4 0.6]]15[2022-03-12 10:09:52] - DEBUG: 第2个特征在各类别下各个特征取值的条件概率为: 16[[0.2 0.2 0.6],[0.2 0.3 0.5]]17[2022-03-12 10:09:52] - DEBUG: 样本预测原始概率为:[[0.01066667 0.024 ]]18[2022-03-12 10:09:52] - INFO: (array([1]), array([[0.49666672, 0.50333328]]))19 20[2022-03-12 10:09:52] - INFO: CategoricalNB 运行结果:21[2022-03-12 10:09:52] - INFO: [1]22[2022-03-12 10:09:52] - INFO: [[0.30769231 0.69230769]]在上述结果中,第17行输出的便是样本[0, 1, 0]的原始预测概率,也就是式CategoricalNB模块的输出结果,之所以第22行中的概率值不一样是因为CategoricalNB在计算条件概率以及先验概率时都先取了
下面,掌柜再通过一个垃圾邮件分类实例来测试上述代码实现。
xxxxxxxxxx131def test_spam_classification():2 x_train, x_test, y_train, y_test = load_data()3 model = MyBayes(alpha=1.0)4 model.fit(x_train, y_train)5 y_pred = model.predict(x_test)6 logging.info(f"My Bayes 运行结果:")7 logging.info(classification_report(y_test, y_pred))8
9 model = CategoricalNB()10 model.fit(x_train, y_train)11 y_pred = model.predict(x_test)12 logging.info(f"CategoricalNB 运行结果:")13 logging.info(classification_report(y_test, y_pred))上述代码便是一个基于朴素贝叶斯模型的垃圾邮件分类示例,这里需要注意的是在对文本进行表示的时候采用的是不考虑词频的词袋模型,具体做法可以参见文章文本特征表示与模型复用第7.1节内容。
上述代码运行结束后便可以看到如下所示的结果:
xxxxxxxxxx191[2022-03-12 13:43:07] - INFO: My Bayes 运行结果:2[2022-03-12 13:43:07] - INFO: precision recall f1-score support3
4 0 0.97 0.96 0.97 15045 1 0.96 0.97 0.97 14976
7 accuracy 0.97 30018 macro avg 0.97 0.97 0.97 30019weighted avg 0.97 0.97 0.97 300110
11[2022-03-12 13:43:08] - INFO: CategoricalNB 运行结果:12[2022-03-12 13:43:08] - INFO: precision recall f1-score support13
14 0 0.97 0.96 0.97 150415 1 0.96 0.97 0.97 149716
17 accuracy 0.97 300118 macro avg 0.97 0.97 0.97 300119weighted avg 0.97 0.97 0.97 3001可以看到,两者在各项评估指标上并没有任何差异。
4 总结
在这篇文章中,掌柜首先简单回顾了朴素贝叶斯算法的基本原理和计算示例;然后分别详细介绍了朴素贝叶斯中样本分布及特征取值的统计、先验概率和条件概率的计算、极大化后验概率的代码实现;最后,分别以模拟数据和真实的文本数据来测试了实现代码的正确性。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎点赞分享!若有任何疑问与建议,请添加掌柜微信nulls8(备注来源)或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1]李航,统计机器学习,清华大学出版社
[2]Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.


