各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
在前面几章的示例介绍中,我们所用到的数据集都是已经处理好的数据,换句话说这些数据集的每个特征维度都已经转换成了可用于计算的数值形式。但是在实际的建模任务中,我们拿到的数据集可能并不是这样的形式。例如接下来要完成的一个任务,对中文垃圾邮件进行分类。
7.1词袋模型7.1.1理解词袋模型7.1.2 文本分词7.1.3 构造词表7.1.4 文本向量化7.1.5 考虑词频的文本向量化7.1.6 小结7.2 基于贝叶斯算法的垃圾邮件分类7.2.1 载入原始文本7.2.2 制作数据集7.2.3 训练模型7.2.4 复用模型7.2.5 小结7.3 考虑权重的词袋模型7.3.1 理解TF-IDF模型7.3.2 TF-IDF计算原理7.3.3 TF-IDF计算示例7.3.4 TF-IDF示例代码7.3.5 小结7.4 词云图7.4.1生成词云图7.4.2自定义样式7.4.3小结引用推荐阅读
7.1词袋模型
例如,对于下面这样一个邮件(样本),应该采用什么样的方式来对其进行量化呢?同时,我们知道在建模过程中需要保证每个样本的特征维度数都一样,但是这里每一封邮件的长度却并不同,这又该怎么处理呢?接下来,笔者就开始介绍机器学习中的第一种文本向量化方法——词袋模型(Bag Of Words, BOW)。
“股权分置已经牵动全国股民的心,是机会?是陷阱?是机会您应该如何把握?是陷阱您应该如何规避?请点击此网址索取和-讯专家团针对股权分置的操作指导:http://www.spam.com/gwyqxjqxx/ ”
7.1.1理解词袋模型
什么是词袋模型呢?其实词袋模型这个叫法非常形象,凸出了模型的核心思想。所谓词袋模型就是,首先将训练样本中所有不重复的词放到这个袋子中构成一个词表(字典);然后再以这个词表为标准来遍历每一个样本,如果词表中对应位置的词出现在了样本中,那么词表对应位置就用1来表示,没有出现就用0来表示;最后,对于每个样本来说都将其向量化成了一个和词表长度一样的只含有0和1的向量。
如图7-1所示为一个直观的词袋模型转换示意图。左边为原始数据集(包含两个样本),中间为词表,右边为向量化的结果。

其中[1 1 0 1]的含义就是,样本“机器学习 是 人工智能 的 子集”中,有3个词都出现在了词表当中,分别是“机器学习”、“人工智能”和“子集”。
具体步骤可以总结为以下3步:
1) 文本分词
首先需要将原始数据的每个样本都进行分词处理(英文语料可以跳过这步);
2) 构造词表
然后在所有的分词结果中去掉重复的部分,保证每个词语只出现一次,且同时要以任意一种顺序来固定词表中每个词的位置。
3) 文本向量化
遍历每个数据样本,若词表中的词出现在该样本中,则对应位置为1,没出现则为0。
在如图7-1中,对样本“机器学习 是 人工智能 的 子集”来说,其中有3个词都出现在了词表中,所以词表中每个词的对应位置为1,而‘深度学习’这个词并没有出现在样本中,所以对应位置为0。
可以看出,向量化后每个样本特征维度的长度都和词表长度相同(图7-1中为4)。虽然这样做的好处是词表包含了样本中所有出现过的词,但是这却很容易导致维度灾难。因为通常一个一般大小的中文数据集,都可能会出现数万个词语(而这意味着转化后向量的维度也有这么大)。所以实际处理中,在分词结束后通常还会进行词频统计这一步,即统计每个词在数据集中出现的次数,然后只选择其中出现频率最高的前K个词作为最终的词表。最后,通常也会将一些无意义的虚词,即停用词(Stop Words)去掉,例如“的,啊,了,”等。
7.1.2 文本分词
经过7.1.1节的介绍可以知道,向量化的第一步是需要对文本进行分词。下面笔者将开始介绍一款常用的开源分词工具jieba。当然,使用jieba库的前提是先要安装,读者可以先进入到对应的虚拟环境中,然后通过命令pip install jieba进行安装。
这里先用下面这段文本来进行分词处理并做词频统计:
央视网消息:当地时间11日,美国国会参议院以88票对11票的结果通过了一项动议,允许国会“在总统以国家安全为由决定征收关税时”发挥一定的限制作用。这项动议主要针对加征钢铝关税的232调查,目前尚不具有约束力。动议的主要发起者——共和党参议员鲍勃·科克说,11日的投票只是一小步,他会继续推动进行有约束力的投票。
可以看到,这段文本当中还包含了很多标点符号和数字,显然暂时不需要这些内容,所以在分词的时候可以通过正则表达式来进行过滤。同时,jieba库分别提供了两种分词模式来应对不同场景下的中文分词,下面分别进行介绍。完整代码见Chapter07/01_cut_words.py文件。
1) 普通分词模式
普通分词模式指的就是按照常规的分词方法,将一个句子分割成多个词语的组成形式,代码如下:
xxxxxxxxxx71import jieba,re2def cutWords(s, cut_all=False):3 cut_words = []4 s = re.sub("[A-Za-z0-9\:\·\—\,\。\“ \”]", "", s)5 seg_list = jieba.cut(s, cut_all=cut_all)6 cut_words.append(" ".join(seg_list))7 print(cut_words)在上述代码中,第4行代码作用是将所有字母、数字、冒号、逗号、句号等过滤掉;第5-6行用来完成分词处理的过程,当cut_all = False,表示普通分词模式。根据上述代码分词结束后便能看到如下所示的结果:
xxxxxxxxxx11['央视网 消息 当地 时间 日 美国国会参议院 以票 对票 的 结果 通过 了 一项 动议 允许 国会 在 总统 以 国家 安全 为 由 决定 征收 关税 时 发挥 一定 的 限制 作用 这项 动议 主要 针对 加征 钢铝 关税 的 调查 目前 尚 不 具有 约束力 动议 的 主要 发起者 共和党 参议员 鲍勃 科克 说 日 的 投票 只是 一 小步 他会 继续 推动 进行 有 约束力 的 投票']但是,对于有的句子来说可以有不同的分词方法,例如“美国国会参议院”这段描述,既可以分成“美国 国会 参议院”,也可以是“美国国会 参议院”,甚至都可以直接是“美国国会参议院”,不同的人可能有不同的切分方式。因此, jieba还提供了另外一种全分词模式。
2) 全分词模式
当把上面代码中cut_all设置为True后,便可以开启全分词模式,分词后的结果如下:
xxxxxxxxxx11['央视 央视网 视网 消息 当地 时间 日 美国 美国国会 美国国会参议院 国会 参议 参议院 议院 以 票 对 票 的 结果 通过 了 一项 动议 允许 许国 国会 在 总统 以 国家 家安 安全 为 由 决定 征收 关税 时 发挥 一定 的 限制 制作 作用 这项 动议 主要 针对 加征 钢 铝 关税 的 调查 目前 尚不 不具 具有 约束 约束力 动议 的 主要 发起 发起者 共和 共和党 党参 参议 参议员 议员 鲍 勃 科克 说 日 的 投票 只是 一小 小步 他 会 继续 推动 进行 有 约束 约束力 的 投票']可以看出对于有的句子,分词后的结果确实看起来结结巴巴的,而这就是全分词模式的作用。在分词结束后,下面就开始对分词结果进行词频统计并构造词表。
7.1.3 构造词表
上面介绍到,分词后通常还会先进行词频统计,以选取出现频率最高的前K个词来构造词表。对词频统计需要用到另外一个包collection中的Counter计数器(如果没有安装可自行安装,命令为 pip install collection)。但是需要注意的是,像上面那样分词后的形式并不能做词频统计,因为Counter是将list中的一个元素视为一个词,所以要对上面的代码略微进行修改。完整代码见Chapter07/01_cut_words.py文件。
xxxxxxxxxx101def wordsCount(s):2 cut_words = ""3 s = re.sub("[A-Za-z0-9\:\·\—\,\。\“ \”]", "", s)4 seg_list = jieba.cut(s, cut_all=False)5 cut_words += (" ".join(seg_list))6 all_words = cut_words.split()7 c = Counter()8 for x in all_words:9 if len(x) > 1 and x != '\r\n':10 c[x] += 1在上述代码中,前6行便是先用来对文本进行分词处理;然后再通过后面4行代码来完成词频统计。经过上述代码的词频统计后,便可以取前K个词来构造词表,代码如下:
xxxxxxxxxx71 # 此处接上面代码2 vocab = []3 print('\n词频统计结果:')4 for (k, v) in c.most_common(5): # 输出词频最高的前5个词5 print("%s:%d" % (k, v))6 vocab.append(k)7 print("词表:", vocab)这样便能得到前K(这里取的5)个词构成的词表,结果如下:
xxxxxxxxxx71词频统计结果:2动议:33关税:24主要:25约束力:26投票:27词表: ['动议', '关税', '主要', '约束力', '投票']7.1.4 文本向量化
通过上面的操作,便能得到一个最终的词表(Vocabulary)。最后一步的向量化工作则是遍历每个样本,查看词表中每个词是否出现在当前样本中,如果出现则词表对应维度用1表示,没出现用0表示。完整代码见Chapter07/02_vectorization.py文件,关键代码如下所示:
xxxxxxxxxx121def vetorization(s):2 # #此处接文本分词和词频统计代码3 x_vec = []4 for item in x_text:5 tmp = [0] * len(vocab)6 for i, w in enumerate(vocab):7 if w in item:8 tmp[i] = 19 x_vec.append(tmp)10 print("词表:", vocab)11 print("文本:", x_text)12 print(x_vec)在上述代码中,第3行里x_text表示原始文本分词后的结果;第4行里tmp表示先初始化一个长度为词表长度的全0向量;第6-8行表示开始遍历每一句文本中的每一个词,判断其是否存在于词表中,如果存在则将tmp向量对应处置为1。
这样,根据vetorization函数便能够对输入的文本进行向量化表示,结果如下:
xxxxxxxxxx51s=['文本分词工具可用于对文本进行分词处理','常见的用于处理文本的分词处理工具有很多']2vetorization(s)3词表: ['文本', '分词', '处理', '工具', '用于', '进行', '常见', '很多']4文本:[['文本','分词','工具','可','用于', '对','文本','进行', '分词', '处理'], ['常见', '的', '用于', '处理', '文本', '的', '分词', '处理', '工具', '有','很多']]5[[1, 1, 1, 1, 1, 1, 0, 0], [1, 1, 1, 1, 1, 0, 1, 1]]从上面的结果可以看出,这里选择了出现频率最高的前8个词来构造词表,然后得到了每个样本的向量化表示。
到此,笔者就介绍完了第一种基本的文本向量化表示方法,即判断样本中的每一个词是否出现在词表中,如果出现则词表对应位置就用1来表示,没有包含则用0表示。最终就会得到一个仅包含0,1的向量来表示这一样本。但这是这样做的弊端之一就是没有考虑到词的出现频率,即不管一个词出现了多少次,最后都仅仅用1来表示其出现过。但在一些场景下,词频又是十分重要的。因此,接下来再来看另外一个种同时考虑词频的词袋表示模型。
7.1.5 考虑词频的文本向量化
如图7-2所示,最上面为原始样本,中间为词表,最下边为两种词袋模型的表示结果。其中左边的表示方法就是我们在上面介绍的第一种文本表示方法,它只考虑词表中的单词是否出现,而不关心出现次数;而右边的表示方法同时还考虑到了每个词的出现频率。
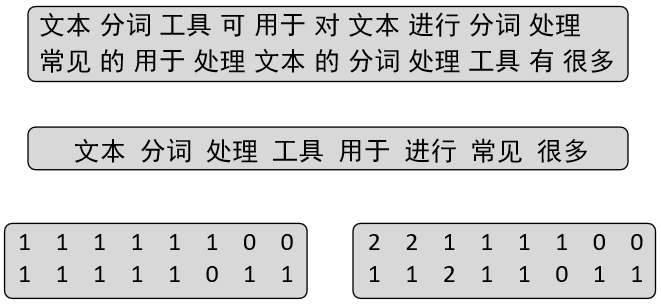
因此,根据这一原理只需要将7.1.4节中的代码稍作修改即可实现这一结果。完整代码见Chapter07/03_vectorization_with_freq.py文件,关键代码如下:
xxxxxxxxxx121def vectorization_with_freq(s):2 #此处接文本分词和词频统计代码3 x_vec = []4 for item in x_text:5 tmp = dict(zip(vocab, [0] * len(vocab)))6 for w in item:7 if w in vocab:8 tmp[w] += 19 x_vec.append(list(tmp.values()))10 print("词表:", vocab)11 print("文本:", x_text)12 print(x_vec)在上述代码中,第5行用来初始化一个字典,其key为词表中的每一个词,value初始化为0表示每个词出现的次数为0;第6-8行用来遍历样本中的每一个词,如果其出现在词表中,则对字典中对应词的计数值加1;最后第9行用来取字典对应的所有value值做这条文本的向量化表示。
这样,根据vetorization_with_freq函数便能够对输入的文本进行向量化表示,结果如下:
xxxxxxxxxx51s =['文本分词工具可用于对文本进行分词处理', '常见的用于处理文本的分词处理工具有很多']2vectorization_with_freq(s)3词表: ['文本', '分词', '处理', '工具', '用于', '进行', '常见', '很多']4文本: [['文本', '分词', '工具', '可', '用于', '对', '文本', '进行', '分词', '处理'], ['常见','的','用于', '处理','文本','的','分词','处理','工具','有','很多']]5[[2, 2, 1, 1, 1, 1, 0, 0], [1, 1, 2, 1, 1, 0, 1, 1]]这样,便得到了考虑词频的文本向量化表示。不过,其实这一方法在sklearn中已经实现了。接下来就通过sklearn中的方法再进行一次示例。在sklearn中,可以通过导入CountVectorizer这一类方法来完成上诉步骤,代码如下:
xxxxxxxxxx71from sklearn.feature_extraction.text import CountVectorizer2count_vec = CountVectorizer(max_features=8, token_pattern=r"(?u)\b\w\w+\b")3x = count_vec.fit_transform(s).toarray()4vocab = count_vec.vocabulary_5vocab = sorted(vocab.items(), key=lambda x: x[1])6print(vocab)7print(x)在上述代码中,第2行里的max_features=8表示取频率最高的前8个词来构造词表;第4-5行代码分别用来获得词表,以及将词表进行排序。
这样,根据上述代码便能够对文本进行向量化表示,结果如下:
xxxxxxxxxx31[('分词', 0), ('处理', 1), ('工具', 2), ('常见', 3), ('很多', 4), ('文本', 5), ('用于', 6), ('进行', 7)]2[[2 1 1 0 0 2 1 1]3 [1 2 1 1 1 1 1 0]]可以发现,通过CountVectorizer类得到的文本向量与上面我们自己编写代码输出的结果存在着一点差别。细心的读者可以发现,导致这一差别的主要原因便是词表的顺序不一样。由于最后的文本向量化形式会依赖于每个词在词表中的位置顺序,所以根据不同顺序的词表最后得到的向量必定存在着不同。但这本质上并没有什么不同,只要词表一样那两者得到的向量表示都是等价的。
7.1.6 小结
在本节中,笔者首先介绍了第一种将文本转化为向量的词袋模型;接着介绍了一款常用的中文分词工具jieba库,并演示了如何通过jieba进行分词处理并进行词频统计;然后介绍了如何实现词袋模型的最后一步向量化表示;最后还介绍了另外一种词袋模型表示方法,该方法同时考虑到了词语的出现频率,并且在长文本的表示中用得较多。
7.2 基于贝叶斯算法的垃圾邮件分类
接下来,笔者就采用第2种词袋模型表示方法通过朴素贝叶斯算法来对垃圾邮件进行分类。下面用到的是一个中文的邮件分类数据集,包含垃圾邮件和非垃圾邮件两类,即一个2分类任务。其中ham_5000.utf8和spam_5000.utf8这两个文件中分别包含有5000封正常邮件和垃圾邮件,文件中每行分别表示一封邮件,示例如下
“我的意中人是一个盖世英雄,有一天他会踩着七色的云彩来娶我,我猜中了前头,可是我猜不着这结局”世间一切美好都有有效期限吧,坦然面对,接受幸福的彩排。
总的来说,要完成这一文本分类任务,首先需要载入原始文本并对其中的每一个样本进行分词处理;接着通过上面介绍的CountVectorizer类来完成文本的向量化表示,并制作完成每个样本对应的类别构成一个完整的数据集;最后再来根据朴素贝叶斯算法来完成最后的分类任务。完整代码见Chapter07/04_bag_of_word_cla.py文件。
7.2.1 载入原始文本
首先需要完成的便是编写一个用于载入本地文本并同时进行分词的函数,代码如下:
xxxxxxxxxx91def load_data_and_cut(file_path='./data/ham_100.utf8'):2 x_cut = []3 with open(file_path, encoding='utf-8') as f:4 for line in f:5 line = line.strip('\n')6 seg_list = jieba.cut(clean_str(line), cut_all=False)7 tmp = " ".join(seg_list)8 x_cut.append(tmp)9 return x_cut在上述代码中,第3行用来打开一个本地的文本文件,并采用utf-8的编码格式进行读取;第4行用来读取文本中的每一行文本;第5行用来去掉每行文本末尾的换行符;第6-7行用来对文本进行清洗以及分词处理,其中函数clean_str的作用是去掉一个字符串中的所有非中文字符;最后再返回处理好的结果。
7.2.2 制作数据集
在完成原始文本的载入后,就需要根据样本的数量来分别构造垃圾邮件和正常邮件对应的类别标签,同时再对文本进行向量化表示,代码如下:
xxxxxxxxxx121def get_dataset(top_k_words=1000):2 x_pos = load_data_and_cut(file_path='./data/ham_5000.utf8')3 x_neg = load_data_and_cut(file_path='./data/spam_5000.utf8')4 y_pos, y_neg = [1] * len(x_pos), [0] * len(x_neg)5 x, y = x_pos + x_neg, y_pos + y_neg6 X_train, X_test, y_train, y_test = \7 train_test_split(x, y, test_size=0.3, random_state=42)8 count_vec = CountVectorizer(max_features=top_k_words)9 X_train = count_vec.fit_transform(X_train)10 X_test = count_vec.transform(X_test)11 # print(len(count_vec.vocabulary_)) # 输出词表长度12 return X_train, X_test, y_train, y_test在上述代码中,第2-3行分别用来载入原始的正常邮件和垃圾邮件;第4-5行分别用来构造样本标签,以及将两个类别的特征输入和标签放到一起;第6-7行用来将原始数据进行打乱,同时划分成训练集与测试集两个部分;第8-10行则是先实例化类CountVectorizer,然后通过训练集来构造词表并对训练集进行向量化,最后再用通过训练集得到的词表来对测试集进行向量化;第12行则是将最后的结果进行返回。
这里特别需要注意的地方就是,一定要先划分数据,然后再进行向量化。这就同第4章中介绍的标准化流程一样,一定要用在训练集上得到的标准化参数(指词表)来对测试集进行标准化(指向量化)。
7.2.3 训练模型
在制作完成数据集后,就可以定义朴素贝叶斯模型,然后进行训练与预测,代码如下:
xxxxxxxxxx61from sklearn.naive_bayes import MultinomialNB2def train(X_train, X_test, y_train, y_test):3 model = MultinomialNB()4 model.fit(X_train, y_train)5 y_pre = model.predict(X_test)6 print(classification_report(y_test, y_pre))在上述代码中,第3行用来定义一个多项式的朴素贝叶斯模型;第4-5行用来训练模型和对测试集进行测试;最后可以得到如下所示的评估结果:
xxxxxxxxxx41 precision recall f1-score support2 accuracy 0.96 30013 macro avg 0.96 0.96 0.96 30014 weighted avg 0.96 0.96 0.96 3001同时,在实例化类MultinomialNB时,还可以通过其对应的模型参数alpha来设定平滑系数的取值。在默认情况下,alpha=1即拉普拉斯平滑。
7.2.4 复用模型
在实际的运用环境中,不可能每次在对新数据进行预测时都从头开始训练一个模型。通常,模型在第1次训练完成后都会被保存下来。只要后续不需要再对模型做任何改动,那么在对新数据进行预测时,只需要载入已有的模型进行复用即可[1]。
1) 保存模型
首先需要定义一个函数来对传入的模型进行保存,代码如下:
xxxxxxxxxx51import joblib2def save_model(model, dir='MODEL'):3 if not os.path.exists(dir):4 os.mkdir(dir)5 joblib.dump(model, os.path.join(dir, 'model.pkl'))在上述代码中,第3-4行用来判断当前是否存在MODEL这个目录,如果不存在则创建;第5行用来将传入的模型以model.pkl的名称保存到MODEL这个目录中。此时,只需要在7.2.3中第5行代码前插入代码save_model(model, dir='MODEL')即可完成对模型的保存。
2) 复用模型
在复用模型之前,需要先定义个函数来对已有的模型进行载入,代码如下:
xxxxxxxxxx61def load_model(dir='MODEL'):2 path = os.path.join(dir, 'model.pkl')3 if not os.path.exists(path):4 raise FileNotFoundError(f"{path} 模型不存在,请先训练模型!")5 model = joblib.load(path)6 return model在上述代码中,第2-4行用来判断给定的路径中是否存在一个名为model.pkl的模型文件,如果不存在则进行提示;第5-6行用来返回载入后的模型。此时,只要已存在的模型载入成功,那么便可以直接用起来对新数据进行预测,代码如下:
xxxxxxxxxx41def predict(X):2 model = load_model()3 y_pred = model.predict(X)4 print(y_pred)到此,对于文本数据的数据预处理过程、向量化过程、以及模型的训练和复用过程就介绍完了。不过,如果读者这里稍微举一反三的话就会发现,在保存模型的时候不仅仅是要对最后的分类或者回归模型进行保存,最开始的数据集预处理模型同样需要保存,例如这里的CountVectorizer模型。因为新输入的数据一般也都是原始数据,需要对其进行相应的标准化(这里是向量化)处理,同时还必须使用通过训练集得到的参数来对新数据进行标准化,所以也需要对标准化时的模型进行保存。
7.2.5 小结
在这节中,笔者首先以一个真实的垃圾邮件数据集为例,详细介绍了如何通过sklearn中的朴素贝叶斯模型(MultinomialNB)来完成文本的分类任务,包括载入原始本文数据、制作数据集、划分数据集等;然后还介绍了如何通过joblib模块来完成模型的复用;最后还分析了复用模型时不仅仅需要保存最后的回归或者分类模型,同时还应该保存数据预处理过程中所用到的所有模型。
7.3 考虑权重的词袋模型
在7.1节中,笔者介绍了两种基本的用于文本表示的词袋模型表示方法,两者之间的唯一区别就是一个考虑的词频而另外一个没有考虑。下面我们再介绍另外一种应用更为常见和广泛使用的词袋模型表示方式——TF-IDF表示方法。
7.3.1 理解TF-IDF模型
之所以陆续的会出现不同的向量化表示形式,其最终目的都只有一个,即尽可能准确的对原始文本进行表示。TF-IDF为词频-逆文档频率(Term Frequence – Inverse Document Frequence)的简称。首先需要明白的是TF-IDF实际上是TF与IDF两者的乘积。同时,出现TF-IDF的原因在于,通常来说在一个样本中一次词出现的频率越高,其重要性应该对应越高,即考虑到词频对文本向量的影响;但是如果仅仅只是考虑到这一个因素则同样会带来一个新的弊端,即有的词不只是在某个样本中出现的频率高,其实它在整个数据集中的出现频率都很高,而这样的词往往也是没有意义的。因此,TF-IDF的做法是通过词的逆文档频率来加以修正调整。
7.3.2 TF-IDF计算原理
TF-IDF的计算过程总体上可以分为两步,先统计词频,然后计算逆文档频率,最后将两者相乘得到TF-IDF值[1]。
1) 统计词频
2) 计算逆文档频率
其中log表示取自然对数。
根据式可以发现,如果一个词越是常见,那么对应的分母就越大,逆文档频率就越小。分母之所以要加1,是为了避免分母为0时(当使用自定义词表时)的平滑处理。这就是最原始的IDF计算方式。不过这种做法的一个瑕疵就是,当所有样本中都含有某个词的时候,计算出来的IDF就为负数。因此,sklearn在实现IDF计算时采用了另外一种平滑处理的方式
这样就同时避免了上面所出现的两种情况。在后面的计算示例中,笔者也将采用式中的公式来计算IDF值。
3) 计算TF-IDF
最后,根据计算得到的TF和IDF值便可以根据式来计算TF-IDF值。同时,对于数据集中的每一个词都能计算得到对应的TF-IDF值,最后将所有的值组合成一个矩阵便得到了文本的向量化表示。
注意:对于样本中的每一个词,如果其没有出现在词表中,那么对应的TF-IDF值为0。
7.3.3 TF-IDF计算示例
现在假设有如下4个样本(每个样本为列表中的一个元素)
xxxxxxxxxx41corpus = ['this is the first document',2 'this document is the second document',3 'and this is the third one',4 'is this the first document']同时,其对应的词表为
xxxxxxxxxx21vocabulary = ['this', 'document', 'first', 'is', 'second', 'the',2 'and', 'one']1) 统计词频
首先,根据已知的样本和词表,可以得到如下所示的一个词频统计矩阵
xxxxxxxxxx41[[1 1 1 1 0 1 0 0]2 [1 2 0 1 1 1 0 0]3 [1 0 0 1 0 1 1 1]4 [1 1 1 1 0 1 0 0]]其中矩阵中的每一行表示对应样本中,词表中各个词出现的次数。例如第1行中的前4个1表示词表中的前4个词均在样本“this is the first document”中出现;第5个0表示词表中的“second”并没有在第一个样本中出现;第6个1表示词表中的“the”出现在第1个样本中;最后两个0表示词表中“and”和“one”这两个词也没有出现在第一个样本中。词频矩阵中的其它3行也是同理。
2) 计算逆文档频率
由式可知,对于词表中的每一个词,根据其在整个样本中的出现情况都可以计算得到一个IDF值。因此,对于整个词表来说,可以计算得到如下所示的一个IDF向量
xxxxxxxxxx11[1. 1.223 1.510 1. 1.916 1. 1.916 1.916]例如对于单词“document”来说它出现在了3个样本中,因此其计算过程为
3) 计算TF-IDF
在计算得到样本中每一个词的词频,以及词表中每一个词的IDF值后,便可以根据计算得到样本中每一个词的TF-IDF值,最终得到如下所示的TF-IDF权重矩阵
xxxxxxxxxx41[[1. 1.223 1.510 1. 0. 1. 0. 0. ]2 [1. 2.446 0. 1. 1.916 1. 0. 0. ]3 [1. 0. 0. 1. 0. 1. 1.916 1.916 ]4 [1. 1.223 1.510 1. 0. 1. 0. 0. ]]例如对于第2个样本来说:
词表中的第1个词“this”在该样本中的出现的次数为1,所以其TF-IDF值为
词表中的第2个词“document” 在该样本中的出现的次数为2,所以其TF-IDF值为
词表中的第3个词“first” 在该样本中的出现的次数为0,所以其TF-IDF值为
同样,对于其它样本TF-IDF值的计算也可以按照上述过程进行,读者们可以自行进行验算。这样,我们就将原始的文本表示转换成了TF-IDF形式的数值表示。
7.3.4 TF-IDF示例代码
对于上述整个计算过程,可以使用sklearn中的CountVectorizer类和TfidfTransformer类来完成,完整代码见Chapter07/05_tf_idf.py文件。关键代码如下:
xxxxxxxxxx101from sklearn.feature_extraction.text import TfidfTransformer2from sklearn.feature_extraction.text import CountVectorizer34if __name__ == '__main__':5 count = CountVectorizer(vocabulary=vocabulary)6 count_matrix = count.fit_transform(corpus).toarray()7 tfidf_trans = TfidfTransformer(norm=None)8 tfidf_matrix = tfidf_trans.fit_transform(count_matrix)9 idf_vec = tfidf_trans.idf_10 print(tfidf_matrix.toarray())在上述代码中,第5行用来实例化类CountVectorizer,并同时传入词表;第6行用来对原始数据进行词频统计;第7-8行代码用来计算整个TF-IDF矩阵。同时,count_martrix是词频统计矩阵;tfidf_matrix是TF-IDF权重矩阵,也就是7.3.3节计算TF-IDF中的结果;idf_vec是IDF向量。
但在默认情况下,第3行代码中的参数norm的值为’l2’,也就是说此时TfidfTransformer会对TF-IDF权重矩阵的每一行进行标准化,即标准化后每一行的模为1。同时,在上面示例中,设置norm为None只是为了复现7.3.2中TF-IDF的计算过程,方便读者理解。
最后,需要解释一下的地方是上述代码第6行和第10行后面的toarray()方法。根据7.1节介绍的内容可以知道,利用词袋模型来表示文本通常来说维度会比较高,当样本较多时词表中可能会有数万或者是数十万个词。因此,在这种情况下对于每个样本来说,其通过词袋模型转换后的特征向量中都会存在大量的0,从而使得最后得到的特征矩阵非常稀疏(Sparse)。所以,为了提高存储效率,在sklearn中这样的稀疏矩阵都会采用稀疏方式进行存储。例如7.3.4节中,tfidf_matrix的第1行采用稀疏表示的结果为
xxxxxxxxxx51(0, 5) 1.02(0, 3) 1.03(0, 2) 1.51082562376599074(0, 1) 1.22314355131420975(0, 0) 1.0其中第1行的含义是原始矩阵中第0行第5列的值是1;同理第3行的含义是原始矩阵中第0行第2列的值是1.510。注意,这里的所索引都是从0开始。并且可以发现,对于原始矩阵中取值为0的位置在稀疏矩阵中并没有被体现出来,这也就极大的节省了变量的存储空间。所以,当有需要查看原始非稀疏矩阵的结果时,就可以通过toarray()方法来转换得到。不过在sklearn中,不管样本特征采用的是稀疏表示方法还是非稀疏表示方法,都可以直接用来进行建模。
7.3.5 小结
在本节中,笔者首先介绍了什么是TF-IDF,以及为什么需要使用到TF-IDF;接着介绍了TF-IDF的计算原理,并同时用真实的示例演示了TF-IDF的整个计算过程;最后介绍了如何通过sklearn中的CountVectorizer类和TfidfTransformer类来完成整个计算过程。
7.4 词云图
在介绍完文本的向量化表示方法后,这里再顺便介绍一个实用的对文本按权重(频率)进行可视化的Python包word cloud。根据word cloud,可以将词语以权重大小或者是词频高低来生成词云图,如图7-3所示。

图7-3所展示的词云图是根据宋词分词统计后所形成的结果,其中字体越大表示其出现的频率越高或者是TF-IDF权重越大。
7.4.1生成词云图
在生成词云图之前,首先需要统计得到词频或者是TF-IDF权重。接下来,以一个宋词数据集为例进行介绍。完整代码见Chapter07/06_word_cloud.py文件。
1) 载入原始文本
首先,这里需要载入原始的宋词数据,代码如如下:
xxxxxxxxxx111def load_data_and_cut(file_path='./data/QuanSongCi.txt'):2 cut_words = ""3 with open(file_path, encoding='utf-8') as f:4 for line in f:5 line = line.strip('\n')6 if len(line) < 20:7 continue8 seg_list = jieba.cut(clean_str(line), cut_all=False)9 cut_words += (" ".join(seg_list))10 all_words = cut_words.split()11 return all_words可以看到,上述代码和7.1.3节中的基本一样,所以在此就不再赘述。
2) 统计词频
接下来,通过Counter计数器来完成分词结果中词频的统计,代码如下:
xxxxxxxxxx91def get_words_freq(all_words, top_k=500):2 c = Counter()3 for x in all_words:4 if len(x) > 1 and x != '\r\n':5 c[x] += 16 vocab = {}7 for (k, v) in c.most_common(top_k):8 vocab[k] = v9 return vocab在上述代码中,第2行用来定义一个计数器;第5行用来对每个词进行计数;第6-8行用来查找出现频率最高的前top_k个词,并将词和出现频率以字典的形式进行存储。
3) 生成词云图
在得到词频字典后,便可以通过WordCloud类来完成词云图的生成,代码如下:
xxxxxxxxxx91def show_word_cloud(word_fre):2 word_cloud = WordCloud(font_path='./data/simhei.ttf',3 background_color='white', max_font_size=70)4 word_cloud.fit_words(word_fre)5 plt.imshow(word_cloud)6 plt.xticks([]) # 去掉横坐标7 plt.yticks([]) # 去掉纵坐标8 plt.tight_layout()9 plt.show()在上述代码中,第2行用来载入汉字字体,因为word cloud默认不支持汉字;第4行用来生成词云图;第5-6行用来展示最后生成的词云图。在运行完上述代码后,便可以得到如图7-3所示的词云图。可以发现,全词中出现频率最高的几个词便是“人家”、“东风”、“何处”、“风流”等。
7.4.2自定义样式
通过word cloud除了能够生成类似7-3所示的矩形词云图以外,更多场景下我们希望能够生成自定义样式的词云图。例如一个人的形状、一个建筑的形状等。在word cloud中,只需要在实例化对象WordCloud时传入一个掩码矩阵即可完成这一想法。完整代码见Chapter07/07_word_cloud.py文件。
xxxxxxxxxx121def show_word_cloud(word_fre):2 from PIL import Image3 img = Image.open('./data/dufu.png')4 img_array = np.array(img)5 word_cloud = WordCloud(font_path='./data/simhei.ttf',6 background_color='white', max_font_size=70, mask=img_array)7 word_cloud.fit_words(word_fre)8 plt.imshow(word_cloud)9 plt.xticks([]) # 去掉横坐标10 plt.yticks([]) # 去掉纵坐标11 plt.tight_layout()12 plt.show()在运行完上述代码后,便可以生成一个自定义形状的词云图,如图7-4右所示。

在上述代码中,第3-4行用来打开一张图片,并同时转换为一个矩阵;第6行在实例化类WordCloud时需要将这个矩阵赋值到mask参数。这样便能够生成自定义样式的词云图。这里需要注意的一个地方就是,选择的这张图片的背景一定要是纯白色的,因为WordCloud的填充原理就是在图片的非白色趋于进行填充。如果使用的是一张非白色背景的图片,那么最后生成的词云图依旧是一个矩形。
7.4.3小结
在本节中,笔者首先介绍了什么是词云图;接着介绍了如何根据得到的词频统计结果通过word cloud工具来生成词云图;最后还介绍了如何生成自定义形状的词云图。
总结以下,在本章中笔者首先介绍了两种文本处理领域中常见的词袋模型,一步一步详细介绍了整个文本向量化的处理流程;接着介绍了如何使用朴素贝叶斯算法来完成中文垃圾邮件的分类任务,同时也介绍了如何复用模型,包括存储模型和载入模型;其次介绍了文本处理领域中使用最为频繁的TF-IDF表示方法以及对应的计算过程;最后介绍了一种常见的文本可视化手段,即以词和其对应的词频为参数,通过word cloud工具来生成相应的词云图。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎点赞转发分享!若有任何疑问与建议,请添加掌柜微信nulls8或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1] Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
推荐阅读
[2] 第2章 从零认识线性回归(附高清PDF与教学PPT)
[3] 第3章 从零认识逻辑回归(附高清PDF与教学PPT)
[4] 第4章 模型的改善与泛化(附高清PDF与教学PPT)


