1 引言
各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
在前面的文章中掌柜虽然已经详细地介绍了KNN的基本思想与原理,但对于具体的实现细节掌柜并没有过多的介绍。在这篇文章中,掌柜将会详细的来介绍如何从零完成KNN模型的构建,包括
2
在文章[1]中掌柜也介绍过,
因此,首先我们需要定义
2.1
由于在KNN的预测结果中需要根据训练样本给出每个预测样本的标签值,因此就需要知道每个训练样本的原始标签值,故需要在节点中保存每个样本索引。最终,
xxxxxxxxxx91class Node(object):2 def __init__(self, data=None, index=-1):3 self.data = data4 self.left_child = None5 self.right_child = None6 self.index = index7
8 def __str__(self):9 return f"data({self.data}),index({int(self.index)})"在上述代码中,第2-6行定义了节点Node中保存的具体信息,包括样本点、左右子树以及在原始样本中的索引;第8-9行定义了__str__()方法,其作用是在使用print()函数时可以直接打印出节点的信息,而不必用node.data这样的形式来访问节点中的样本。
2.2
在完成
xxxxxxxxxx91class MyKDTree(object):2 def __init__(self, points):3 self.root = None4 self.dim = points.shape[1]5 points = np.hstack(([points, np.arange(0, len(points)).reshape(-1, 1)]))6 self.insert(points, order=0) # 递归构建KD树7
8 def is_empty(self):9 return not self.root在上述代码中,第3行定义了points)的最后一列附加上每个样本点的索引值;第6行则是调用insert()方法递归完成
接下来便是完成insert()方法的实现过程,代码如下:
xxxxxxxxxx181 def insert(self, data, order=0):2 if len(data) < 1:3 return4 data = sorted(data, key=lambda x: x[order % self.dim]) # 按某个维度进行排序5 logging.debug(f"当前待划分样本点:{data}")6 idx = len(data) // 27 node = Node(data[idx][:-1], data[idx][-1])8 logging.debug(f"父节点:{data[idx]}")9 left_data = data[:idx]10 logging.debug(f"左子树: {left_data}")11 right_data = data[idx + 1:]12 logging.debug(f"右子树: {right_data}")13 logging.debug("============")14 if self.is_empty():15 self.root = node # 整个KD树的根节点16 node.left_child = self.insert(left_data, order + 1) # 递归构建左子树17 node.right_child = self.insert(right_data, order + 1) # 递归构建右子树18 return node在上述代码中,第2-3行用来判断当前传入样本是否为空,如果为空则结束当前递归;第4行用于将当前样本按照某个维度的大小顺序进行排序,其中样本点维度的比较顺序为从左到右依次轮询,order在每次进行递归时都会累加;第6-7行行用来获取并保存当前样本点排序后中间位置的样本并保存到一个新初始化的节点中;第9、11行则是分别取当前排序后样本的左边部分和右边部分,以此来分别作为当前节点的左右子树;第16-17行则是分别递归构建左右子树。
上述logging模块的详细用法可以参加文章训练模型时如何保存训练日志?[3]
2.3
在实现
xxxxxxxxxx111def test_kd_tree_build(points):2 logging.debug("MyKDTree 运行结果:")3 logging.debug("构建KD树")4 tree = MyKDTree(points)5 logging.debug("构建结束")6 logging.debug("MyKDTree 层次遍历结果:")7 tree.level_order()8 9if __name__ == '__main__':10 points = np.array([[2, 5], [1, 4], [3, 3], [6, 5], [10, 2.], [7, 3], [8, 13], [8, 9], [1, 2]])11 test_kd_tree_build(points)在上述代码中,第4行便是根据传入的样本点来递归的构建
以上代码运行结束后便会有类似如下信息输出:
xxxxxxxxxx351[2022-03-06 10:05:47] - DEBUG: MyKDTree 运行结果:2[2022-03-06 10:05:47] - DEBUG: 构建KD树3[2022-03-06 10:05:47] - DEBUG: 当前待划分样本点:[array([1., 4., 1.]), array([1., 2., 8.]), array([2., 5., 0.]), array([3., 3., 2.]), array([6., 5., 3.]), array([7., 3., 5.]), array([ 8., 13., 6.]), array([8., 9., 7.]), array([10., 2., 4.])]4[2022-03-06 10:05:47] - DEBUG: 父节点:[6. 5. 3.]5[2022-03-06 10:05:47] - DEBUG: 左子树: [array([1., 4., 1.]), array([1., 2., 8.]), array([2., 5., 0.]), array([3., 3., 2.])]6[2022-03-06 10:05:47] - DEBUG: 右子树: [array([7., 3., 5.]), array([ 8., 13., 6.]), array([8., 9., 7.]), array([10., 2., 4.])]7[2022-03-06 10:05:47] - DEBUG: ============8[2022-03-06 10:05:47] - DEBUG: 当前待划分样本点:[array([1., 2., 8.]), array([3., 3., 2.]), array([1., 4., 1.]), array([2., 5., 0.])]9[2022-03-06 10:05:47] - DEBUG: 父节点:[1. 4. 1.]10[2022-03-06 10:05:47] - DEBUG: 左子树: [array([1., 2., 8.]), array([3., 3., 2.])]11[2022-03-06 10:05:47] - DEBUG: 右子树: [array([2., 5., 0.])]12[2022-03-06 10:05:47] - DEBUG: ============13[2022-03-06 10:05:47] - DEBUG: 当前待划分样本点:[array([1., 2., 8.]), array([3., 3., 2.])]14[2022-03-06 10:05:47] - DEBUG: 父节点:[3. 3. 2.]15[2022-03-06 10:05:47] - DEBUG: 左子树: [array([1., 2., 8.])]16[2022-03-06 10:05:47] - DEBUG: 右子树: []17......18
19层次遍历结果为:20[2022-03-06 10:05:47] - DEBUG: 第1层的节点为:21[2022-03-06 10:05:47] - DEBUG: <p([6. 5.]), idx(3)>22 23[2022-03-06 10:05:47] - DEBUG: 第2层的节点为:24[2022-03-06 10:05:47] - DEBUG: <p([1. 4.]), idx(1)>25[2022-03-06 10:05:47] - DEBUG: <p([8. 9.]), idx(7)>26
27[2022-03-06 10:05:47] - DEBUG: 第3层的节点为:28[2022-03-06 10:05:47] - DEBUG: <p([3. 3.]), idx(2)>29[2022-03-06 10:05:47] - DEBUG: <p([2. 5.]), idx(0)>30[2022-03-06 10:05:47] - DEBUG: <p([10. 2.]), idx(4)>31[2022-03-06 10:05:47] - DEBUG: <p([ 8. 13.]), idx(6)>32
33[2022-03-06 10:05:47] - DEBUG: 第4层的节点为:34[2022-03-06 10:05:47] - DEBUG: <p([1. 2.]), idx(8)>35[2022-03-06 10:05:47] - DEBUG: <p([7. 3.]), idx(5)>在上述输出结果中,第3-17行便是
根据层次遍历以及构建输出结果,也可以还原得到如图1所示的
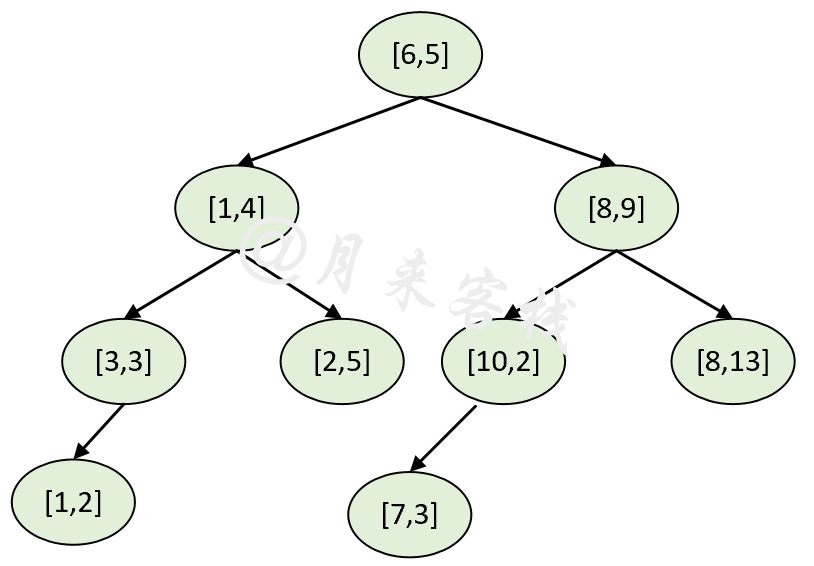
2.4
在文章K近邻算法中掌柜详细介绍了
xxxxxxxxxx131bestNode, bestDist = None, inf2def NearestNodeSearch(curr_node):3 if curr_node == None:4 return5 if distance(curr_node, bestNode) <bestDist:6 bestDist = distance(curr_node, bestNode)7 bestNode = curr_node8 if q_i < curr_node_i:9 NearestNodeSearch(curr_node.left)10 else:11 NearestNodeSearch(curr_node.right)12 if |curr_node_i - q_i| < bestDist:13 NearestNodeSearch(curr_node.other)在实现最近邻的搜索过程之前,需要先给出距离的定义。这里掌柜使用的是Minkowski距离,即:
当
xxxxxxxxxx21def distance(p1, p2, p=2):2 return np.sum((p1 - p2) ** p) ** (1 / p)进一步,根据上述
xxxxxxxxxx291 def nearest_search(self, point):2 best_node = None3 best_dist = np.inf4 visited = [] # 用来记录哪些节点被访问过5 point = point.reshape(-1)6
7 def nearest_node_search(point, curr_node, order=0):8 nonlocal best_node, best_dist, visited # 声明这三个变量不是局部变量9 logging.debug(f"当前访问节点为:{curr_node}")10 visited.append(curr_node)11 if curr_node is None:12 return None13 dist = distance(curr_node.data, point)14 logging.debug(f"当前访问节点到被搜索点的距离为:{round(dist, 3)},"15 f"全局最佳距离为:{round(best_dist, 3)}, 全局最佳点为:{best_node}\n")16 if dist < best_dist:17 best_dist = dist18 best_node = curr_node19 cmp_dim = order % self.dim20 if point[cmp_dim] < curr_node.data[cmp_dim]:21 nearest_node_search(point, curr_node.left_child, order + 1)22 else:23 nearest_node_search(point, curr_node.right_child, order + 1)24 if np.abs(curr_node.data[cmp_dim] - point[cmp_dim]) < best_dist:25 child = curr_node.left_child if curr_node.left_child not in 26 visited else curr_node.right_child27 nearest_node_search(point, child, order + 1)28 nearest_node_search(point, self.root, 0)29 return best_node, best_dist在上述代码中,第2-4行定义了相关的全局记录变量;第8行则是用来声明这三个遍历不是局部变量而是上面定义的全局变量;第10行则是用来记录当前哪些节点已经访问过;第13行是计算当前节点到被搜索点的距离;第16-18行则是判断是否要更新当前最佳节点;第19行是计算得到进入左右子树时的判断维度;第20-23行是根据维度比较信息递归遍历相应的左子树或右子树;第24-27行则是根据子空间排除原理来判断当前节点左右子树中未访问过的节点是否存在最佳节点,并进行递归遍历。
最后,可以通过如下方式来进行
xxxxxxxxxx151def test_kd_nearest_search(points):2 tree = MyKDTree(points)3 p = np.array([[5.9, 3]])4 best_node, best_dist = tree.nearest_search(p)5 logging.debug("MyKDTree 运行结果:")6 logging.debug(f"离样本点{p}最近的节点是:{best_node},距离为:{round(best_dist, 3)}")7
8 kd_tree = KDTree(points)9 dist, ind = kd_tree.query(p, k=1)10 logging.debug("sklearn KDTree 运行结果:")11 logging.debug(f"离样本点{p}最近的节点是:{points[ind]},距离为:{dist}")12 13if __name__ == '__main__':14 points = np.array([[2, 5], [1, 4], [3, 3], [6, 5], [10, 2.], [7, 3], [8, 13], [8, 9], [1, 2]])15 test_kd_nearest_search(points)上述代码运行结束后便会输出类似如下的结果:
xxxxxxxxxx291[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:data([6. 5.]),index(3)2[2022-03-06 14:15:34] - DEBUG: 当前访问节点到被搜索点的距离为:2.002,全局最佳距离为:inf, 全局最佳点为:None3
4[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:data([1. 4.]),index(1)5[2022-03-06 14:15:34] - DEBUG: 当前访问节点到被搜索点的距离为:5.001,全局最佳距离为:2.002, 全局最佳点为:data([6. 5.]),index(3)6
7[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:data([3. 3.]),index(2)8[2022-03-06 14:15:34] - DEBUG: 当前访问节点到被搜索点的距离为:2.9,全局最佳距离为:2.002, 全局最佳点为:data([6. 5.]),index(3)9
10[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:None11[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:data([2. 5.]),index(0)12[2022-03-06 14:15:34] - DEBUG: 当前访问节点到被搜索点的距离为:4.383,全局最佳距离为:2.002, 全局最佳点为:data([6. 5.]),index(3)13
14[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:None15[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:data([8. 9.]),index(7)16[2022-03-06 14:15:34] - DEBUG: 当前访问节点到被搜索点的距离为:6.357,全局最佳距离为:2.002, 全局最佳点为:data([6. 5.]),index(3)17
18[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:data([10. 2.]),index(4)19[2022-03-06 14:15:34] - DEBUG: 当前访问节点到被搜索点的距离为:4.22,全局最佳距离为:2.002, 全局最佳点为:data([6. 5.]),index(3)20
21[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:data([7. 3.]),index(5)22[2022-03-06 14:15:34] - DEBUG: 当前访问节点到被搜索点的距离为:1.1,全局最佳距离为:2.002, 全局最佳点为:data([6. 5.]),index(3)23
24[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:None25[2022-03-06 14:15:34] - DEBUG: 当前访问节点为:None26[2022-03-06 14:15:34] - DEBUG: MyKDTree 运行结果:27[2022-03-06 14:15:34] - DEBUG: 离样本点[[5.9 3. ]]最近的节点是:data([7. 3.]),index(5),距离为:1.128[2022-03-06 14:15:34] - DEBUG: sklearn KDTree 运行结果:29[2022-03-06 14:15:34] - DEBUG: 离样本点[[5.9 3. ]]最近的节点是:[[[7. 3.]]],距离为:[[1.1]]根据上述输出结果,可以得知距离样本点[5.9,3]最近的样本点是[7,3],并且整个KD树的搜索过程将如图2所示。
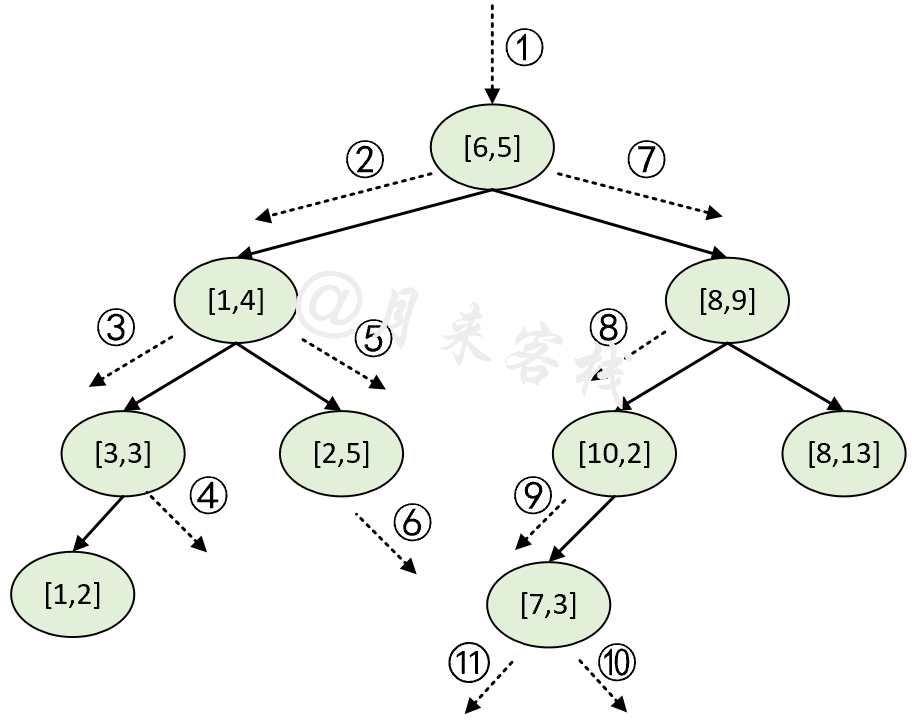
2.5
同样,在文章[1]中掌柜已经详细介绍了
xxxxxxxxxx161KNearestNodes, n = [], 02def NearestNodeSearch(curr_node):3 if curr_node == None:4 return5 if n < K:6 KNearestNodes.insert(curr_node) # 插入后保持有序7 if n >= K and8 distance(curr_node, q) < distance(curr_node, KNearestNodes[-1]):9 KNearestNodes.pop()10 KNearestNodes.insert(curr_node) # 插入后保持有序11 if q_i < curr_node_i:12 NearestNodeSearch(curr_node.left)13 else:14 NearestNodeSearch(curr_node.right)15 if n < K or | curr_node_i - q_i | < distance(q, KNearestNodes[-1]):16 NearestNodeSearch(curr_node.other)在实现K近邻搜索之前,我们先来定义一个辅助函数用于对节点进行插入并排序,代码如下:
xxxxxxxxxx51 def append(k_nearest_nodes, curr_node, point):2 k_nearest_nodes.append(curr_node)3 k_nearest_nodes = sorted(k_nearest_nodes,4 key=lambda x: distance(x.data, point))5 return k_nearest_nodes在上述代码中,第2行是将当前节点加入到k_nearest_nodes中;第3-4行是根据k_nearest_nodes中每个样本点到被搜索点的距离来进行升序排序。
进一步,根据上述伪代码逻辑,便可以实现得到
xxxxxxxxxx301 def _k_nearest_search(self, point, k):2 k_nearest_nodes = []3 visited = []4 n = 05 6 def k_nearest_node_search(point, curr_node, order=0):7 nonlocal k_nearest_nodes, n8 if curr_node is None:9 return None10 visited.append(curr_node)11 if n < k: # 如果当前还没找到k个点,则直接进行保存12 n += 113 k_nearest_nodes = self.append(k_nearest_nodes, curr_node, point)14 else: # 已经找到k个局部最优点,开始进行筛选15 dist = (distance(curr_node.data, point) < distance(point, k_nearest_nodes[-1].data))16 if dist:17 k_nearest_nodes.pop() # 移除最后一个18 k_nearest_nodes = self.append(k_nearest_nodes, curr_node, point) # 加入新的点并进行排序19 cmp_dim = order % self.dim20 if point[cmp_dim] < curr_node.data[cmp_dim]:21 k_nearest_node_search(point, curr_node.left_child, order + 1)22 else:23 k_nearest_node_search(point, curr_node.right_child, order + 1)24 if n < k or np.abs(curr_node.data[cmp_dim] - point[cmp_dim]) < distance(point,25 k_nearest_nodes[-1].data):26 child = curr_node.left_child if curr_node.left_child not in 27 visited else curr_node.right_child28 k_nearest_node_search(point, child, order + 1)29 k_nearest_node_search(point, self.root, 0)30 return k_nearest_nodes在上述代码中,第2-4行定义了相关的全局记录变量;第8行则是用来声明这三个遍历不是局部变量而是上面定义的全局变量;第10行用来记录访问过的节点;第11-13行是判断如果当前还没找到K个点,则直接进行保存;第14-18行是判断如果已经找到K个局部最优点,则开始进行筛选;第19-23行则是根据当前比较维度来判断进入左子树还是右子树进行递归遍历;第24-28行是根据子空间排除原理来判断当前节点左右子树中未访问过的节点是否存在最佳节点,并进行递归遍历。
到此,对于任一点的K近邻查找就已经实现完毕了,下面只需要再定义一个函数即可循环完成多个样本点的K近邻搜索过程,代码如下:
xxxxxxxxxx131 def k_nearest_search(self, points, k):2 result_points = []3 result_ind = []4 for point in points:5 k_nodes = self._k_nearest_search(point, k)6 tmp_points = []7 tmp_ind = []8 for node in k_nodes:9 tmp_points.append(node.data)10 tmp_ind.append(int(node.index))11 result_points.append(tmp_points)12 result_ind.append(tmp_ind)13 return np.array(result_points), np.array(result_ind)最后,可以通过如下方式来进行
xxxxxxxxxx161def test_kd_k_nearest_search(points):2 tree = MyKDTree(points)3 p = np.array([[10, 3], [8.9, 4], [2, 9.], [5, 5]])4 k_best_nodes, ind = tree.k_nearest_search(p, k=3)5 logging.debug("MyKDTree 运行结果:")6 logging.debug(k_best_nodes)7 logging.debug(ind)8
9 logging.debug("sklearn KDTree 运行结果:")10 kd_tree = KDTree(points)11 dist, ind = kd_tree.query(p, k=3)12 logging.debug(points[ind])13 logging.debug(ind)14if __name__ == '__main__':15 points = np.array([[2, 5], [1, 4], [3, 3], [6, 5], [10, 2.], [7, 3], [8, 13], [8, 9], [1, 2]])16 test_kd_k_nearest_search(points)上述代码运行结束后便会输出类似如下的结果:
xxxxxxxxxx261正在查找离样本点[10. 3.]最近的3个样本点!2[2022-03-06 15:29:15] - DEBUG: K近邻搜索当前访问节点为:data([6. 5.]),index(3)3[2022-03-06 15:29:15] - DEBUG: 当前K近邻中的节点为(已按距离排序):4[2022-03-06 15:29:15] - DEBUG: data([6. 5.]),index(3) 5
6[2022-03-06 15:29:15] - DEBUG: K近邻搜索当前访问节点为:data([8. 9.]),index(7)7[2022-03-06 15:29:15] - DEBUG: 当前K近邻中的节点为(已按距离排序):8[2022-03-06 15:29:15] - DEBUG: data([6. 5.]),index(3),data([8. 9.]),index(7) 9
10[2022-03-06 15:29:15] - DEBUG: K近邻搜索当前访问节点为:data([10. 2.]),index(4)11[2022-03-06 15:29:15] - DEBUG: 当前K近邻中的节点为(已按距离排序):12[2022-03-06 15:29:15] - DEBUG: data([10. 2.]),index(4),data([6. 5.]),index(3),data([8. 9.]),index(7) 13 14[2022-03-06 15:29:15] - DEBUG: K近邻搜索当前访问节点为:None15[2022-03-06 15:29:15] - DEBUG: K近邻搜索当前访问节点为:data([7. 3.]),index(5)16[2022-03-06 15:29:15] - DEBUG: 当前K近邻中的节点为(已按距离排序):17[2022-03-06 15:29:15] - DEBUG: data([10. 2.]),index(4),data([7. 3.]),index(5),data([6. 5.]),index(3) 18...19[2022-03-06 15:29:15] - DEBUG: MyKDTree 运行结果:20[2022-03-06 15:29:15] - DEBUG: [[[10. 2.] [ 7. 3.] [ 6. 5.]], [[ 7. 3.] [10. 2.] [ 6. 5.]], 21 [[ 2. 5.] [ 1. 4.] [ 6. 5.]], [[ 6. 5.] [ 3. 3.] [ 7. 3.]]]22 23 ...24[2022-03-06 15:29:15] - DEBUG: sklearn KDTree 运行结果:25[2022-03-06 15:29:15] - DEBUG: [[[10. 2.] [ 7. 3.] [ 6. 5.]], [[ 7. 3.] [10. 2.] [ 6. 5.]],26 [[ 2. 5.] [ 1. 4.] [ 6. 5.]], [[ 6. 5.] [ 7. 3.] [ 3. 3.]]]到此,对于
3 KNN
在完成
3.1 模型拟合
对于KNN分类模型来说,所谓的模型拟合其实就是根据给定的训练样本来构造完成对应的
xxxxxxxxxx81class KNN(object):2 def __init__(self, n_neighbors):3 self.n_neighbors = n_neighbors4
5 def fit(self, x, y):6 self._y = y7 self.kd_tree = MyKDTree(x)8 return self在上述代码中,第2-3行为类KNN的初始化方法,用来保存K值;第5-8行则是模型的拟合过程,即建立
3.2 模型预测
在模型拟合完成后,便可以对新输入的样本进行预测。不过根据k_nearest_search()方法的返回结果可知,K近邻搜索返回的是训练集中K个节点对应的索引位置,因此需要先根据索引取到对应的标签值,然后再根据取到的标签通过投票法来确定新样本的类别。故,此处需要先定义一个辅助函数来完成类别的确定,实现代码如下:
xxxxxxxxxx111 def get_pred_labels(query_label):2 y_pred = [0] * len(query_label)3 for i, label in enumerate(query_label):4 max_freq = 05 count_dict = {}6 for l in label:7 count_dict[l] = count_dict.setdefault(l, 0) + 18 if count_dict[l] > max_freq:9 max_freq = count_dict[l]10 y_pred[i] = l11 return np.array(y_pred)在上述代码中,第1行query_label是一个二维数组,query_label[i] 表示离第i个样本最近的k个样本点对应的正确标签;第3-10行则是分别开始遍历每个样本的预测结果;第6-19行是根据投票规则来确定当前样本的所属类别。
进一步,我们便可以通过如下方式来完成新样本的预测:
xxxxxxxxxx51 def predict(self, x):2 k_best_nodes, ind = self.kd_tree.k_nearest_search(x, k=self.n_neighbors)3 query_label = self._y[ind]4 y_pred = self.get_pred_labels(query_label)5 return y_pred最后,掌柜以iris数据集为例来进行实验,并同时与sklearn中KNeighborsClassifier的分类结果进行对比。
xxxxxxxxxx121if __name__ == '__main__':2 x_train, x_test, y_train, y_test = load_data()3 k = 54 model = KNeighborsClassifier(n_neighbors=k)5 model.fit(x_train, y_train)6 y_pred = model.predict(x_test)7 logging.info(f"impl_by_sklearn 准确率:{accuracy_score(y_test, y_pred)}")8
9 my_model = KNN(n_neighbors=k)10 my_model.fit(x_train, y_train)11 y_pred = my_model.predict(x_test)12 logging.info(f"impl_by_ours 准确率:{accuracy_score(y_test, y_pred)}")上述代码运行结束后的结果如下所示:
xxxxxxxxxx21[2022-03-06 21:52:42] - INFO: impl_by_sklearn 准确率:0.95555555555555562[2022-03-06 21:52:42] - INFO: impl_by_ours 准确率:0.9555555555555556从上述结果可以看出,两者的分类准确率并没有任何差异。
4 总结
在这篇文章中,掌柜首先简单回顾了
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎点赞分享!若有任何疑问与建议,请添加掌柜微信nulls8(备注来源)或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[2]https://en.wikipedia.org/wiki/K-d_tree


