1 引言
各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
在上一篇文章中,掌柜详细介绍了一种常见的朴素贝叶斯算法,也被称之为Categorical Naive Bayes。但实际上,”朴素贝叶斯“算法远不止这一种,而它们之间的主要却别在于对条件概率的处理上[1],即式
在接下来的这篇文章中,掌柜将会介绍第二种基于朴素贝叶斯思想的分类模型,多项朴素贝叶斯(Multinomial Naive Bayes, MNB)
2 多项朴素贝叶斯
在通过Categorical NB来进行文本分类的场景中,在计算条件概率时都是将词表中的每个词以是否出现为标准进行类别化(categorization)处理,因为如果将词频作为特征维度的取值类别,那么将会出现在测试集中特征维度的取值情况数大于训练集中的情况。
例如在训练集中“客栈”这个词出现的最大次数为10,那么模型在拟合过程中就会认为“客栈”这个维度的特征取值有10种情况,并以此进行建模;但是当测试集中的某个样本里“客栈”这个词出现的频次为11时,那么模型便会认为该维度多了一种取值情况,进而无法取到对应的条件概率。
2.1 算法原理
通常,在利用词袋模型对文本进行表示时词频也是一个重要的考量因素,而多项朴素贝叶斯算法在处理这一问题时则是将每个维度的词频在总词频中的占比来作为条件概率进行建模[2]。
在MNB中,我们可以将类别
其中
其中
在根据式
因此,常见的一种做法是在式
进一步,根据
同时对于MNB算法来说,从式
其中
此时根据式
到此,对于多项贝叶斯算法的基本原理就介绍完了,下面掌柜再来通过一个实际的计算示例来帮助大家更加清晰地理解。
2.2 计算示例
假设现在有一批基于词袋模型表示的文本数据,其一共包含有
根据式
各类别下不同特征取值的条件概率为(设
其中分子中的
同理,对于其它情况来说,对应的条件概率为
根据计算得到的先验概率、条件概率和式
同理,其它两个类别的后验概率分别为
根据上述结果可知,样本
3 多项贝叶斯实现
在有了前面Categorical贝叶斯算法的实现经验后,Multinomial贝叶斯的实现过程就非常容易理解了。下面,掌柜依旧分步进行讲解实现。需要说明的是以下实现代码均参考自sklearn 0.24.0 中的MultinomialNB模块,只是对部分处理逻辑进行了修改与简化。
3.1 特征计数实现
通过第2.1节的内容可知,不管是计算先验概率还是条件概率,在这之前都需要先统计训练集中各个样本及样本特征取值的分布情况。因此,这里首先需要初始化相关的计数器;然后再对样本和特征样本特征取值的分布情况进行统计。
如下代码所示便是对两个重要计数器初始化工作:
xxxxxxxxxx71class MyMultinomialNB(object):2 def __init__(self, alpha=0):3 self.alpha = alpha4 self._ALPHA_MIN = 1e-105 def _init_counters(self, ):6 self.class_count_ = np.zeros(self.n_classes, dtype=np.float64)7 self.feature_count_ = np.zeros((self.n_classes, self.n_features_),dtype=np.float64)在上述代码中,第3-4行是初始化平滑项系数alpha。第6行class_count_被初始化成了一个形状为[n_classes,]的全零向量,其中n_classes表示分类的类别数量,而每个维度分别表示每个类别的样本数量(例如[2,2,3]表示0,1,2这三个类别的样本数分别是2,2,3),其目的是后续用于计算每个类别的先验概率。第7行feature_count_被初始化成了一个形状为[n_classes,n_features]的全零矩阵,其中feature_count_[i][j]表示,对于整个训练集来说,在第i个类别中第j个特征的出现频次。
例如:
xxxxxxxxxx11feature_count_ = [[ 6. 31. 36.],[44. 22. 28.],[19. 10. 14.]]那么feature_count_[i][j]表示,对于整个训练集来说,在第i个类别中第j个特征的出现频次为44。
在初始化完两个计数器之后,下面就可以来对样本类别和特征分布进行计数了,代码如下:
xxxxxxxxxx41 def _count(self, X, Y):2 self.class_count_ += Y.sum(axis=0) # shape [n_classes,]3 # 计算得到每个类别下的样本数量4 self.feature_count_ += np.dot(Y.T, X) # [n_classes,n] @ [n,n_features_]在上述代码中,第1行参数Y是原始标签经过one-hot编码后的形式,例如3分类问题中类别1会被编码成[0,1,0]的形式,因此Y的形状为[n,n_classes];第2行代码是计算得到每个类别对应的样本数量,形状为[n_classes,]。第4行则是统计每个类别下所有样本在各个特征维度下的取值频次。
例如:
xxxxxxxxxx91Y = np.array([[1, 0, 0], 2 [0, 0, 1]]) # [2,3]3X = np.array([[3, 7, 2, 9], 4 [5, 7, 8, 8],5 [2, 2, 5, 7]])6print(np.dot(Y.T,X))7 [[1,0,1], [[3, 7, 2, 9], [[5 9 7 16]8===> [0,0,0], @ [5, 7, 8, 8]] = [0 0 0 0 ]9 [0,1,0]] [2, 2, 5, 7] [5 7 8 8 ]]在上述代码中,等号右边第1行5的含义便是在训练样本中第0个类别下第0个特征总频次为3+2;第1行中的9则表示在训练样本中第0个类别下第1个特征总频次为7+2。
进一步,在计算得到训练集中样本及特征的分布情况后,便可以计算先验概率和条件概率。
3.2 先验概率实现
先验概率实现较为简单,整体实现代码如下:
xxxxxxxxxx31 def _update_class_prior(self):2 log_class_count = np.log(self.class_count_)3 self.class_prior_ = log_class_count - np.log(self.class_count_.sum())在上述代码中,第2-3便是用来计算各个类别的先验概率,并同时进行了取对数处理。需要提示一点的是
3.3 条件概率实现
根据式
xxxxxxxxxx51 def _update_feature_prob(self, ):2 smoothed_fc = self.feature_count_ + self.alpha3 smoothed_cc = smoothed_fc.sum(axis=1)4 self.feature_prob_ = (np.log(smoothed_fc) -5 np.log(smoothed_cc.reshape(-1, 1)))从3.1节最后的示例结果可知,feature_count_中每一行求和便是第i个类别下所有特征频次的总和,这对应的便是上述代码第3行;第4-5行代码则是根据式
3.4 模型拟合实现
上述先验概率和条件概率的计算对应便是整个模型的拟合过程,换句话说对于贝叶斯算法来说,所谓的模型拟合就是计算先验概率和条件概率。在实现这部分代码之后,在通过一个函数将整个过程串起来即可,代码如下:
xxxxxxxxxx131 def fit(self, X, y):2 self.n_features_ = X.shape[1]3 labelbin = LabelBinarizer() # 将标签转化为one-hot形式4 Y = labelbin.fit_transform(y) # one-hot 形式标签 shape: [n,n_classes]5 self.classes_ = labelbin.classes_ # 原始标签类别 shape: [n_classes,]6 if Y.shape[1] == 1: # 当数据集为二分类时fit_transform处理后的结果并不是one-hot形式7 Y = np.concatenate((1 - Y, Y), axis=1) # 改变为one-hot形式8 self.n_classes = Y.shape[1] # 数据集的类别数量9 self._init_counters() # 初始化计数器10 self._count(X, Y) # 对各个特征的取值情况进行计数,以计算条件概率等11 self._update_class_prior()12 self._update_feature_prob()13 return self在上述代码中,第2-4行用来将原始[0,1,2,3...]这样的标签转换为one-hot编码形式的标签值,形状为[n,n_classes];第5行用来记录原始的标签类别,形状为[n_classes,];第6-7行用来处理当数据集为二分类时fit_transform处理后的结果并不是one-hot形式,需要添加一列来转换成one-hot形式;第8行是获取数据集的类别数量;第9-13行则分别是上面3节内容介绍到的初始化计数器、特征取值情况统计、计算先验概率和计算条件概率。
3.5 后验概率实现
在完成模型的拟合过程后,对于新输入的样本来说其最终的预测结果则取决于对应的极大后验概率。根据式
xxxxxxxxxx21 def _joint_likelihood(self, X):2 return np.dot(X, self.feature_prob_.T) + self.class_prior_在上述代码中,第2行便是根据拟合得到的条件概率(权重)和先验概率(偏置)来计算得到样本的后验概率。
在实现每个样本后验概率的计算结果后,最后一步需要完成的便是极大化操作,即从所有后验概率中选择最大的概率值对应的类别作为该样本的预测类别即可。实现代码如下所示:
xxxxxxxxxx81 def predict(self, X, with_prob=False):2 from scipy.special import softmax3 jll = self._joint_likelihood(X)4 y_pred = self.classes_[np.argmax(jll, axis=1)]5 if with_prob:6 prob = softmax(jll)7 return y_pred, prob8 return y_pred在上述代码中,第4行便是极大化后验概率的操作;第5-8样则是根据对应的参数来返回预测后的结果。
3.6 使用示例
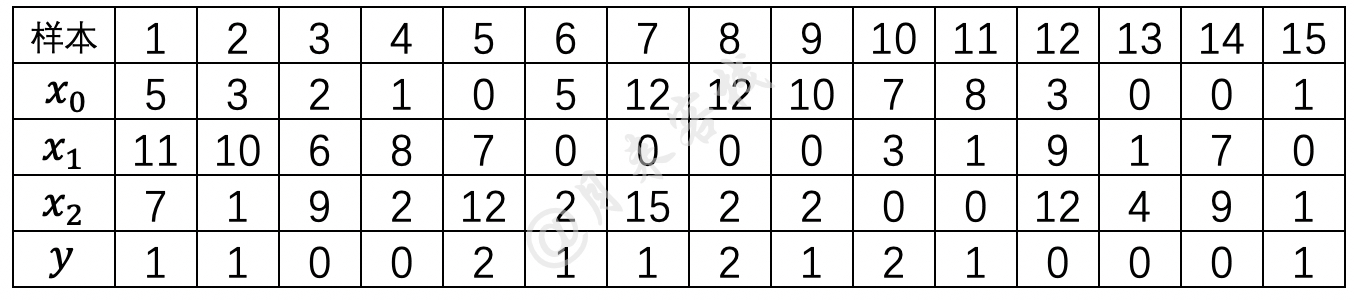
下面,掌柜先以表1中的模拟数据来通过上述实现的代码进行示例。
xxxxxxxxxx281def load_simple_data():2 import numpy as np3 x = np.array([[5, 3, 2, 1, 0, 5, 12, 12, 10, 7, 8, 3, 0, 0, 1],4 [11, 10, 6, 8, 7, 0, 0, 0, 0, 3, 1, 9, 1, 7, 0],5 [7, 1, 9, 2, 12, 2, 15, 2, 2, 0, 0, 12, 4, 9, 1]]).transpose()6 y = np.array([1, 1, 0, 0, 2, 1, 1, 2, 1, 2, 1, 0, 0, 0, 1])7 return x, y8
9def test_naive_bayes():10 x, y = load_simple_data()11 logging.info(f"MyMultinomialNB运行结果:")12 model = MyMultinomialNB(alpha=1.)13 model.fit(x, y)14 logging.info(model.predict(np.array([[17, 25, 39]]), with_prob=True))15 logging.info(f"MultinomialNB 运行结果:")16 model = MultinomialNB(alpha=1.)17 model.fit(x, y)18 logging.info(model.predict(np.array([[17, 25, 39]])))19 logging.info(model.predict_proba(np.array([[17, 25, 39]])))20 21if __name__ == '__main__':22 formatter = '[%(asctime)s] - %(levelname)s: %(message)s'23 logging.basicConfig(level=logging.DEBUG, # 如果需要查看简略信息可将该参数改为logging.INFO24 format=formatter, 25 datefmt='%Y-%m-%d %H:%M:%S',26 handlers=[logging.StreamHandler(sys.stdout)]27 )28 test_naive_bayes()在上述代码中,第2-7行便是构造表1中的模拟数据;第10-14行是根据实现的MyMultinomialNB来进行训练模型并预测;第15-19行则是利用sklearn中的MultinomialNB模块来完成模型训练与预测的工作。 更多与Logging模块的详细使用可参加文章xxxxx。
上述代码运行结束后变换得到类似如下结果:
xxxxxxxxxx201[2022-03-15 20:36:14] - INFO: MyMultinomialNB运行结果:2[2022-03-15 20:36:14] - DEBUG: 各个类别下特征维度的频次为:3[[ 6. 31. 36.]4 [44. 22. 28.]5 [19. 10. 14.]]6[2022-03-15 20:36:14] - DEBUG: 每个类别下的样本数class_count_:[5. 7. 3.]7[2022-03-15 20:36:14] - DEBUG: 计算每个类别的先验概率class_prior_:8[-1.09861229 -0.76214005 -1.60943791]9[2022-03-15 20:36:14] - DEBUG: 各个类别下特征维度的占比为:10[[-2.38482319 -0.86499744 -0.71981543]11 [-0.76804849 -1.43921676 -1.20741515]12 [-0.83290912 -1.43074612 -1.1205912 ]]13[2022-03-15 20:36:14] - DEBUG: 样本预测原始概率为:[[-91.33834415 -96.88857422 -95.24060271]]14[2022-03-15 20:36:14] - INFO: (array([0]), array([[0.97648353, 0.00379516, 0.0197213 ]]))15[2022-03-15 20:36:14] - INFO: MultinomialNB 运行结果:16[[ 6. 31. 36.]17 [44. 22. 28.]18 [19. 10. 14.]]19[2022-03-15 20:36:14] - INFO: [0]20[2022-03-15 20:36:14] - INFO: [[0.97648353 0.00379516 0.0197213 ]]下面,掌柜再通过一个垃圾邮件分类实例来测试上述代码实现。
xxxxxxxxxx131def test_spam_classification():2 x_train, x_test, y_train, y_test = load_data()3 logging.info(f"MyMultinomialNB 运行结果:")4 model = MyMultinomialNB(alpha=1.)5 model.fit(x_train.toarray(), y_train)6 y_pred = model.predict(x_test.toarray())7 logging.info(classification_report(y_pred, y_test))8
9 logging.info(f"MultinomialNB 运行结果:")10 model = MultinomialNB(alpha=1.)11 model.fit(x_train, y_train)12 y_pred = model.predict(x_test)13 logging.info(classification_report(y_pred, y_test))上述代码便是一个基于朴素贝叶斯模型的垃圾邮件分类示例,需要注意的是在对文本进行表示的时候采用的是TF-IDF模型,具体做法可以参见文章文本特征表示与模型复用第7.1节内容。
上述代码运行结束后便可以看到如下所示的结果:
xxxxxxxxxx231[2022-03-15 21:12:07] - INFO: MyMultinomialNB 运行结果:2[2022-03-15 21:12:07] - INFO: 3 precision recall f1-score support4
5 0 0.93 0.99 0.96 14186 1 0.99 0.94 0.96 15837
8 accuracy 0.96 30019 macro avg 0.96 0.96 0.96 300110weighted avg 0.96 0.96 0.96 300111
12[2022-03-15 21:12:07] - INFO: MultinomialNB 运行结果:13
14[2022-03-15 21:12:07] - INFO: 15 precision recall f1-score support16
17 0 0.93 0.99 0.96 141818 1 0.99 0.94 0.96 158319
20 accuracy 0.96 300121 macro avg 0.96 0.96 0.96 300122weighted avg 0.96 0.96 0.96 300123
4 总结
在这篇文章中,掌柜首先介绍了多项朴素贝叶斯的基本原理;然后通过一个实际的示例对其原理进行了进一步解释与阐述;接着一步一步详细地介绍了多项贝叶斯的实现方法;最后,掌柜分别以模拟数据和真实的文本数据来测试了实现代码的正确性。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎点赞分享!若有任何疑问与建议,请添加掌柜微信nulls8(备注来源)或文末留言进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1]https://scikit-learn.org/stable/modules/naive_bayes.html#naive-bayes
[2] Rennie J D, Shih L, Teevan J, et al. Tackling the poor assumptions of naive bayes text classifiers[C] (ICML-03). 2003: 616-623.https://www.aaai.org/Papers/ICML/2003/ICML03-081.pdf
[3]https://nlp.stanford.edu/IR-book/html/htmledition/naive-bayes-text-classification-1.html
[4训练模型时如何保存训练日志?
[5]文本特征提取与模型的复用
[6]示例代码:https://github.com/moon-hotel/MachineLearningWithMe


