1 引言
各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
在前面一篇文章中,掌柜详细介绍了ID3与C4.5决策树算法的原理与计算示例,并且还介绍了如何借助开源的sklearn框架来完成整个建模的搭建流程。在接下来的这篇文章中,掌柜将会详细地来介绍如何从零一步步地实现ID3与C4.5这两种决策树算法。
所有示例代码均可从此仓库获取:https://github.com/moon-hotel/MachineLearningWithMe
2 决策树实现
由ID3与C4.5决策树算法的原理可知,两则的唯一差别就是体现在对于特征划分标准的不同上,前者采用的信息增益,而后者则采用的是信息增益比来进行判断。因此,两则在代码实现时只需要将这部分内容单独抽象成一个函数即可,其它部分的代码可以保持不变。下面,掌柜开始来一步步的进行介绍。
2.1 节点定义
在实现决策树之前,我们需要先来定义决策树中每个节点的构成。参考第8章 决策树与集成学习 第8.3.2节)中决策树可视化例子中的节点信息,这里我们将决策树的节点定义为如下形式:
xxxxxxxxxx121class Node(object):2 def __init__(self, ):3 self.sample_index = None # 保存当前节点中对应样本在数据集中的索引4 self.values = None # 保存每个类别的数量5 self.features = None # 保存当前节点状态时特征集中剩余特征6 self.feature_id = -1 # 保存当前节点对应划分特征的id7 self.label = None # 保存当前节点对应的类别标签(叶子节点才有)8 self.n_samples = 0 # 保存当前节点对应的样本数量9 self.children = {} # 保存当前节点对应的孩子节点10 self.criterion_value = 0.11 self.n_leaf = 0 # 以当前节点为根节点时其叶子节点的个数12 self.leaf_costs = 0. 在上述代码中,第3行sample_index用来保存当前节点中对应样本在数据集中的索引,这样我们在需要的时候可以直接通过索引去取到对应的样本而不是保存到每个节点中,同时也方便根据索引来取对应的样本标签;第4行values用来保存每个类别的数量,例如[10,4,6]则表示第0、1、2这三个类别在当前节点中的数量分别是10、4和6,其作用是根据这一结果可以知道当前叶子节点所代表的类别;第5行features用于保存在当前节点状态时特征集中剩余特征维度(即还剩下哪些特征没有被用于前面的划分中),例如[0,2,3]则表示对于当前节点来说,其备选特征为第0、2和3个;第6行feature_id用于保存当前节点对应划分特征的id,因为在决策树预测阶段时需要知道当前节点是用哪个特征来进行划分的;第7行label用来保存当前节点对应的类别标签(叶子节点才有),不过这个可要可不要,因为通过前面的values就已经能够得到当前叶子节点的类别;第8行n_samples用来保存当前节点对应的样本数量,用于分析观察;第9行children用来保存当前节点对应的所有孩子节点,因为利用ID3和C4.5生成的决策树为n叉树,所以掌柜这里定义了一个字典来进行存储,其中key为特征取值,value为对应的孩子节点,值得一提的是在sklearn框架中采用的是二叉树来进行实现;第10行criterion_value则是用来保存当前节点对应的信息熵;第11行是记录以当前节点为根节点时其叶子节点的个数;第12行是记录以当前节点为根节点时其所有叶子节点的损失和,这两行主要用于后续剪枝部分的代码实现。
同时,为了在打印输出构建好的决策树的能够更加方便,我们需要定义如下方法,代码如下:
xxxxxxxxxx121 def __str__(self):2 return f"<======================>\n" \3 f"当前节点所有样本的索引({self.sample_index})\n" \4 f"当前节点的样本数量({self.n_samples})\n" \5 f"当前节点每个类别的样本数({self.values})\n" \6 f"当前节点对应的信息增益(比)({round(self.criterion_value, 3)})\n" \7 f"当前节点状态时特征集中剩余特征({self.features})\n" \8 f"当前节点状态时划分特征ID({self.feature_id})\n" \9 f"当前节点对应的类别标签为({self.label})\n" \10 f"当前节点为根节点对应孩子节点数为({self.n_leaf})\n" \11 f"当前节点为根节点对应孩子节点损失为({self.leaf_costs})\n" \12 f"当前节点对应的孩子为({self.children.keys()})"这里值得一提的是__str__方法是Python中每个类对象都有的一个方法,只是默认情况下没有进行实现。__str__方法的作用是在通过print函数打印类的实例化对象时输出的便是上面我们定义的信息,而不是默认情况下的对象内存地址。
例如:
xxxxxxxxxx141if __name__ == '__main__':2 node = Node()3 print(node)4# <======================>5# 当前节点所有样本的索引(None)6# 当前节点的样本数量(0)7# 当前节点每个类别的样本数(None)8# 当前节点对应的信息增益(比)(0.0)9# 当前节点状态时特征集中剩余特征(None)10# 当前节点状态时划分特征ID(-1)11# 当前节点对应的类别标签为(None)12# 当前节点为根节点对应孩子节点数为(0)13# 当前节点为根节点对应孩子节点损失为(0)14# 当前节点对应的孩子为(dict_keys([]))2.2 实现思路
在介绍完节点定义部分的内容后,我们便可以根据前面介绍的决策树生成步骤递归地来构建决策树。
输入:训练数据集D,特征集A,阈值
输出:决策树。
(1) 若
(2) 若
(3) 否则,计算
(4) 如果
(5) 否则,对
(6) 对于第
根据上述生成步骤,下面我们先来实现其中需要用到的一些计算方法。
2.3 信息熵与条件熵实现
无论是ID3还是C4.5生成算法都需要计算样本的信息熵、特征的信息熵(在C4.5中)以及在某一特征取值下的条件熵。同时,需要说明的是,在本篇文章中掌柜是以离散型输入特征为例进行的实现讲解,在下一篇文章中再来介绍能够同时处理离散型和连续型特征的实现方式。
根据信息熵计算公式
可知,其代码实现如下:
xxxxxxxxxx201class DecisionTree(object):2 def __init__(self, min_samples_split=2,3 criterion='id3',4 epsilon=1e-5,5 alpha=0.):6 self.root = None7 self.min_samples_split = min_samples_split # 用来控制是否停止分裂8 self.epsilon = epsilon # 用来控制是否停止分裂9 self.criterion = criterion # 划分标注,ID3还是C4.510 self.alpha = alpha11
12 def _compute_entropy(self, y_class):13 y_unique = np.unique(y_class)14 if y_unique.shape[0] == 1: # 只有一个类别15 return 0. # 熵为016 ety = 0.17 for i in range(len(y_unique)): # 取每个类别18 p = np.sum(y_class == y_unique[i]) / len(y_class)19 ety += p * np.log2(p)20 return -ety在上述代码中,第2-10行是定义类DecisionTree的初始化函数,其中第6行是保存决策树的根节点,第7行用来指定节点中停止分裂的最少样本数;第8行用来指定节点停止分裂的最小阈值,第9行指定采用ID3还是C4.5进行特征划分,第10行是后续实现剪枝过程时的惩罚参数;第12行则是定义一个方法来计算信息熵,主要用于ID3和C4.5中计算样本的信息熵,以及C4.5中特征的信息熵;第13行是计算得到当前输入有多少重类别(或特征取值);第14-15行则是判断如果只有一个类别则信息熵为0;第17-19行是分别遍历么一个类别,然后根据式
进一步,在实现完信息熵的计算后,可以根据条件熵的计算公式
来编码实现条件熵的计算,代码如下:
xxxxxxxxxx91 def _compute_condition_entropy(self, X_feature, y_class):2 f_unique = np.unique(X_feature)3 result = 0.4 for i in range(len(f_unique)): 5 index_x = (X_feature == f_unique[i]) 6 p = np.sum(index_x) / len(y_class)7 ety = self._compute_entropy(y_class[index_x]8 result += p * ety 9 return result在上述代码中,第1行X_feature表示数据集中的某一列特征,y_class表示样本的类别标签;第2行是计算得到特征维度中的取值情况;第4行开始是遍历每一个特征取值;第5-6行是取当前特征类别对应的索引以及标签;第7-8行是先计算样本对应的信息熵,然后再计算条件熵。
例如对于如下数据集来说
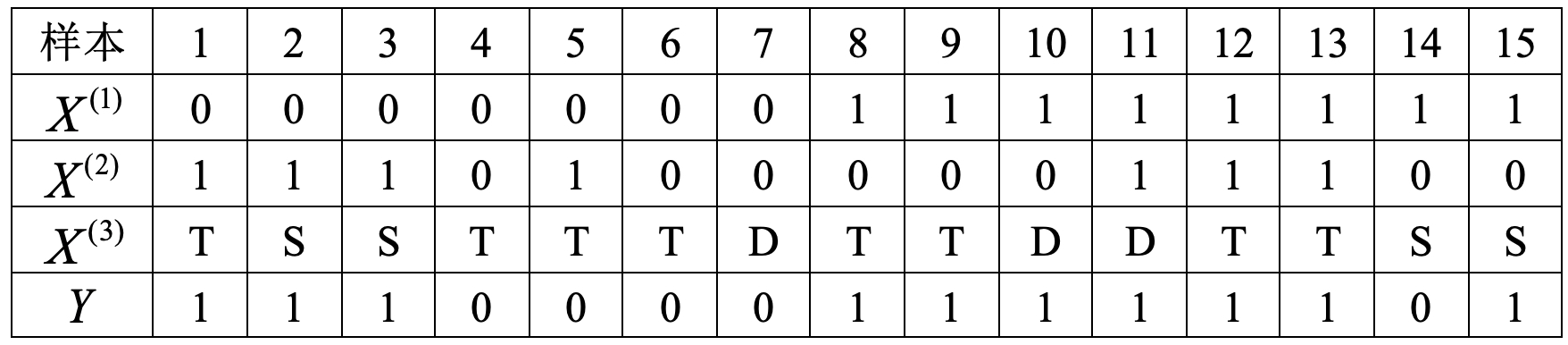
信息熵为
各特征取值下的条件熵为
以上具体计算过程可以参考文章XXX第8.2节内容。
所有示例代码均可从此仓库获取:https://github.com/moon-hotel/MachineLearningWithMe
对于上述计算过程,我们可以通过上面介绍的代码来进行完成,如下所示:
xxxxxxxxxx191def load_simple_data():2 x = np.array([['0', '0', '0', '0', '0', '0', '0', '1', '1', '1', '1', '1', '1', '1', '1'],3 ['1', '1', '1', '0', '1', '0', '0', '0', '0', '0', '1', '1', '1', '0', '0'],4 ['T', 'S', 'S', 'T', 'T', 'T', 'D', 'T', 'T', 'D', 'D', 'T', 'T', 'S', 'S']])5 y = np.array([1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1])6 return x.transpose(), y7
8if __name__ == '__main__':9 x, y = load_simple_data()10 dt = DecisionTree()11 ety = dt._compute_entropy(y)12 print(f"信息熵{ety}")13 for i in range(x.shape[1]):14 print(f"条件熵为{dt._compute_condition_entropy(x[:, i], y)}")15
16# 信息熵0.918295834054489617# 条件熵为0.749674166522435518# 条件熵为0.809447296671752719# 条件熵为0.9090314682266482.4 特征划分标准实现
在实现完信息熵和条件熵的计算过程后,下面我们再来封装一个方法来根据指定参数返回信息增益或者是信息增益比的结果来作为节点划分时的标注,实现代码如下所示:
xxxxxxxxxx101 def _split_criterion(self, ety, X_feature, y_class):2 c_ety = self._compute_condition_entropy(X_feature, y_class) # 3 info_gains = ety - c_ety # 计算信息增益4 if self.criterion == "id3":5 return info_gains6 elif self.criterion == "c45":7 f_ety = self._compute_entropy(X_feature)8 return info_gains / f_ety9 else:10 raise ValueError(f"划分标准 self.criterion = {self.criterion}只能是 id3 和 c45 其中之一!")在上述代码中,第1行的3个参数分别是传入的信息熵、对应的特征列和样本标签;第2行是计算每个特征下的条件熵;第3行是计算对应特征下的信息增益;第4-8行是根据参数来返回对应的划分指标,其中第7行是计算特征对应的信息熵;第10行则是进行错误提示。
2.5 决策树构建实现
在做完前面的整个铺垫过程后,下面就可以正式的来递归构建生成决策树了。由于这部分代码较长,掌柜这里就分成两部分来进行介绍,第一部分实现代码如下所示:
xxxxxxxxxx171 def _build_tree(self, data, f_ids):2 x_ids = np.array(data[:, -1], dtype=np.int).reshape(-1)3 labels = self._y[x_ids] 4 node = Node()5 node.sample_index = x_ids6 node.n_samples = len(labels)7 node.values = np.bincount(labels, minlength=self.n_classes)8 node.features = f_ids9 if self.root is None:10 self.root = node11 y_unique = np.unique(labels) 12 if y_unique.shape[0] == 1 or len(f_ids) < 1 \13 or node.n_samples <= self.min_samples_split:14 node.label = self._get_label(labels) 15 return node16 ety = self._compute_entropy(labels) 17 node.criterion_value = ety在上述代码中,第1行中data表示当前节点中的所有样本点,f_ids表示当前节点中还要哪些特征是可用的(剩余特征);第2行是得到每个样本在原始数据集中的索引,因此在调用_build_tree方法前需要在训练集的最后一列追加上样本索引;第3行是根据样本索引取对应的标签;第4-8行是先定义当前节点并保存对应的节点信息;第9-10行是判断根节点是否为空,如果为空则将当前节点作为根节点;第11-15行是2.2节生成步骤中第(1)和(2)步的体现,同时还增加了最小样本数的判断条件;第14行是根据多数原则确定当前节点对应的类别;第16行是计算当前节点所有样本对应的信息熵。
紧接着,第二部分实现代码如下所示:
xxxxxxxxxx201 max_criterion = 02 best_feature_id = -13 for id in f_ids: 4 criterion = self._split_criterion(ety, data[:, id], labels)5 if criterion > max_criterion: 6 max_criterion = criterion7 best_feature_id = id8 if max_criterion < self.epsilon: 9 node.label = self._get_label(labels) 10 return node11 node.feature_id = best_feature_id12 feature_values = np.unique(data[:, best_feature_id])13 candidate_ids = copy.copy(f_ids)14 candidate_ids.remove(best_feature_id)15
16 for f in feature_values: 17 c = data[:, best_feature_id] == f 18 index = np.array([i for i in range(len(c)) if c[i] == True])19 node.children[f] = self._build_tree(data[index], candidate_ids)20 return node在上述代码中,第3-7行是遍历当前节点可进行选择的划分特征,然后计算各个特征划分下的信息增益(比)来选择最佳特征,这便是2.2节生成步骤后第(3)步的体现;第8-10则是判断当前计算得到的最大划分指标是否小于阈值,如果是则直接返回当前节点,这是生成步骤中第(4)步的体现;第12行是取最佳划分特征中特征的取值情况;第13-14则是从一开始传入的特征列表f_ids中去处此时选中的最佳特征,而之所以要先复制是因为后续要依次遍历最佳特征中的每个特征取值并递归的构建决策树(第19行),而f_ids是一个列表传入函数_build_tree时本质上是传入的地址,这就会导致每次递归操作都是改变之中的值,因此需要先进行复制;第16-19行是依次遍历每个取值情况,然后根据当前特征维度的取值,来取对应的样本索引,并递归的进行节点划分,这是生成步骤中第(5)步的体现。
到此,对于整个决策树的递归构建过程就介绍完了,我们可以通过如下函数来进行决策树的拟合:
xxxxxxxxxx71 def fit(self, X, y):2 self._y = np.array(y).reshape(-1)3 self.n_classes = len(np.bincount(y)) # 得到当前数据集的类别数量4 feature_ids = [i for i in range(X.shape[1])] # 得到特征的序号5 self._X = np.hstack(([X, np.arange(len(X)).reshape(-1, 1)]))6 self._build_tree(self._X, feature_ids) # 递归构建决策树7 self._pruning_leaf()在上述代码中,第1行X,y便是训练时所用到的数据和标签,需要注意的是输入的特征X必须为categorical类型,同时X的形状必须为i[n_samples, n_features],y的形状必须为[n_samples,];第3行是得到当前数据集的类别数量;第4行是得到特征的序号;第5行是在X的右侧追加一列作为每个样本的索引;第6行是开始递归构建决策树;第7行是进行剪枝步骤,这部分内容将在第3节中进行介绍。
2.6 决策树遍历实现
为了便于查看决策树的构建结果,以及在剪枝过程中需要从下往上按层遍历所有节点,所以这里需要实现一个层次遍历的方法。遍历的思路大致是用一个队列来保存当前层的所有节点,然后遍历当前层的所有节点时再将当前层所有节点的孩子节点依次放入到队列中,同时在这一过程中再将每一层的遍历结果保存起来即是最后层次遍历的结果。实现代码如下所示:
xxxxxxxxxx211 def level_order(self, return_node=False):2 root = self.root3 if not root:4 return []5 queue = [root]6 res = []7 while queue:8 tmp = []9 for i in range(len(queue)):10 node = queue.pop(0)11 tmp.append(node)12 for k, v in node.children.items():13 queue.append(v)14 res.append(tmp)15 if return_node:16 return res # 按层次遍历的顺序返回各层节点的地址17 # [[root], [level2 node1, level2_node2], [level3,...] [level4,...],...[],]18 for i, r in enumerate(res):19 logging.debug(f"第{i + 1}层的节点为:")20 for node in r:21 logging.debug(node)在上述代码中,第1行return_node是用来判断返回所有层次遍历的结果(后续剪枝时会用到)还是直接输出遍历结果;第7-14行是按层来遍历所有节点,然后再将所有节点的孩子节点放入到队列中再次循环遍历这些节点,其中tmp是用来保存当前层的所有节点;第15-16行是返回所有层次遍历的结果;第18-21行是直接输出整个层次遍历的结果。
所有示例代码均可从此仓库获取:https://github.com/moon-hotel/MachineLearningWithMe
对于表1中的示例数据来说,在其拟合结束后便可以得到如下所示的层次遍历结果(由于篇幅有限这里就只展示部分输出信息,大家可以自己运行源码进行查看):
xxxxxxxxxx461if __name__ == '__main__':2 x, y = load_simple_data()3 dt = DecisionTree()4 dt.fit(x, y)5 dt.level_order(return_node=False)6
7# 拟合过程部分信息输出8DEBUG: ========>9DEBUG: 当前节点所有样本的索引 [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]10DEBUG: 当前节点的样本数量 1511DEBUG: 当前节点每个类别的样本数 [ 5 10]12DEBUG: 当前节点状态时特征集中剩余特征 [0, 1, 2]13DEBUG: 当前节点中的样本信息熵为 0.918295834054489614DEBUG: 当前节点下特征对应的条件熵为 0.749674166522435515DEBUG: 当前节点第0个特征在标准id3下对应的划分指标为0.168621667532054116DEBUG: 当前节点下特征对应的条件熵为 0.809447296671752717DEBUG: 当前节点第1个特征在标准id3下对应的划分指标为0.1088485373827368118DEBUG: 当前节点下特征对应的条件熵为 0.90903146822664819DEBUG: 当前节点第2个特征在标准id3下对应的划分指标为0.00926436582784151420DEBUG: 此时选择第0个特征进行样本划分21DEBUG: 此时第0个特征的取值为['0' '1']22 23# 层次遍历部分输出结果24DEBUG: 第1层的节点为:25当前节点所有样本的索引([ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14])26当前节点每个类别的样本数([ 5 10]) 当前节点状态时特征集中剩余特征([0, 1, 2])27当前节点状态时划分特征ID(0) 当前节点对应的孩子为(dict_keys(['0', '1']))28
29DEBUG: 第2层的节点为:30当前节点所有样本的索引([0 1 2 3 4 5 6]) 31当前节点每个类别的样本数([4 3]) 当前节点状态时特征集中剩余特征([1, 2])32当前节点状态时划分特征ID(1) 当前节点对应的孩子为(dict_keys(['0', '1']))33
34当前节点所有样本的索引([ 7 8 9 10 11 12 13 14])35当前节点每个类别的样本数([1 7]) 当前节点状态时特征集中剩余特征([1, 2])36当前节点状态时划分特征ID(2) 当前节点对应的孩子为(dict_keys(['D', 'S', 'T']))37
38DEBUG: 第3层的节点为:39当前节点所有样本的索引([3 5 6])40当前节点每个类别的样本数([3 0]) 当前节点状态时特征集中剩余特征([2])41当前节点状态时划分特征ID(-1) 当前节点对应的孩子为(dict_keys([]))42
43当前节点所有样本的索引([0 1 2 4])44当前节点每个类别的样本数([1 3]) 当前节点状态时特征集中剩余特征([2])45当前节点状态时划分特征ID(2) 当前节点对应的孩子为(dict_keys(['S', 'T']))46......在上述运行结果中,特征ID取值0,1,2分别表示表1中的

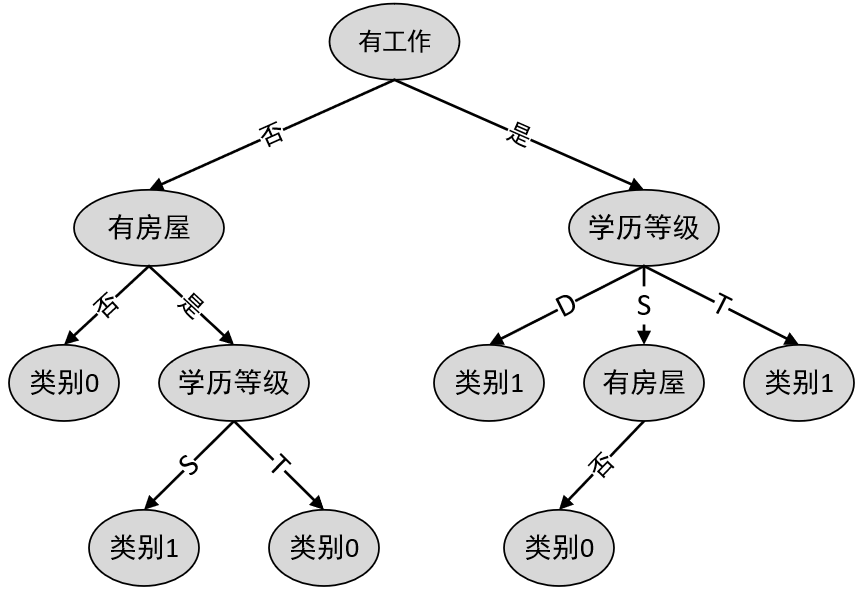
如图1所示便是根据上述代码拟合得到的决策树,其中每个节点中第2行表示样本索引,第3行表示每个类别中样本的数量。例如对于最后一层左边的叶子节点来说,[1,2]表示该节点中包含有原始训练样本中的第1和2行样本,[0,2]表示在这个节点中,类别为0的样本有0个,类别为1的样本后2个。
同时,可以发现,这与我们在前面通过手动计算生成的决策树是一样,如图2所示。
2.7 样本预测实现
在完成决策树的拟合过程后,下一步便是如何来实现决策树的预测过程。总的来讲,新样本的预测思路为:从根节点开始,根据当前节点的划分维度取测试样本中对应的特征维度,然后再根据特征维度的取值进入到当前节点的孩子节点中;然后再迭代进行这一步骤,直到进入到叶子节点或当前节点的孩子节点中不存在满足特征取值的节点时停止,此时取当前节点对应对应的类别作为该测试样本的类别即可。
具体地,我们先来实现一个样本的预测过程,实现代码如下:
xxxxxxxxxx91 def _predict_one_sample(self, x):2 current_node = self.root3 while True:4 current_feature_id = current_node.feature_id5 current_feature = x[current_feature_id]6 if len(current_node.children) < 1 or \7 current_feature not in current_node.children:8 return current_node.values9 current_node = current_node.children[current_feature]在上述代码中,第2行是初始化根节点为当前节点;第4-9行则开始按照上述思路进行遍历;第4-5行是取当前节点进行分裂时所使用到的特征ID,并取新样本x汇总对应的特征值;第6-8行是判断如果当前节点为叶子节点,或者由于数据集不充分当前节点的孩子节点不存在下一个划分节点的某一个取值(例如根据上面测试数据集构造得到的id3树,对于特征['0','1','D']来说,在遍历最后一个特征维度时,取值'D'就不存在于孩子节点中)时,则返回当前节点中各个类别的分布情况,即图1中每个节点的第3行结果;第9行是根据当前新样本x的特征取值进入到当前节点对应的孩子节点中。
所有示例代码均可从此仓库获取:https://github.com/moon-hotel/MachineLearningWithMe
进一步,便可以根据_predict_one_sample方法来循环预测得到测试集中所有样本的类别,实现代码如下:
xxxxxxxxxx81 def predict(self, X):2 results = []3 for x in X:4 results.append(self._predict_one_sample(x))5 results = np.array(results)6 logging.debug(f"原始预测结果为:\n{results}")7 y_pred = np.argmax(results, axis=1)8 return y_pred在上述代码中,第1行X为新输入的测试样本,需要注意的是其形状必须为[n_samples,n_features];第3-4行是循环遍历每个测试样本,并将预测后的结果放到results中;第7行是根据预测得到的样本类别分布结果来计算得到每个样本真实的预测类别。
例如对于如下原始结果来说
xxxxxxxxxx41[[3 0]2[0 2]3[1 3]4[1 1]]
其真实的预测结果为:
xxxxxxxxxx11DecisionTree 预测结果为:[0 1 1 0]2.8 使用示例
以表1中的示例数据为例,DecisionTree 的使用方法如下:
xxxxxxxxxx91def test_decision_tree():2 x, y = load_simple_data()3 dt = DecisionTree(criterion='c45')4 dt.fit(x, y)5 y_pred = dt.predict(np.array([['0', '0', 'T'],6 ['0', '1', 'S'],7 ['0', '1', 'D'],8 ['0', '1', 'T']]))9 logging.info(f"DecisionTree 预测结果为:{y_pred}")上述代码运行结束后,其输出结果便是2.7节末的示例结果。
下面,掌柜再以一个垃圾邮件分类数据集进行示例,该数据采用的是不考虑词频的词袋模型表示方法。
首先我们需要载入数据集,代码如下所示:
xxxxxxxxxx81def load_data():2 x, y = load_spam()3 x_train, x_test, y_train, y_test \4 = train_test_split(x, y, test_size=0.3, random_state=2020)5 vect = VectWithoutFrequency(top_k_words=1000)6 x_train = vect.fit_transform(x_train)7 x_test = vect.transform(x_test)8 return x_train, x_test, y_train, y_test在上述代码中,第2行为载入原始分词后的样本,第5-7行则是分别将训练集和测试集转换为不考虑词频的词袋向量表示。
进一步,便可以构建一个决策树模型来对垃圾邮件进行分类了,代码如下:
xxxxxxxxxx101def test_spam_classification():2 x_train, x_test, y_train, y_test = load_data()3 dt = DecisionTree(criterion="id3")4 dt.fit(x_train, y_train)5 y_pred = dt.predict(x_test)6 logging.info(f"DecisionTree 准确率:{accuracy_score(y_test, y_pred)}")7 model = DecisionTreeClassifier(criterion='entropy')8 model.fit(x_train, y_train)9 y_pred = model.predict(x_test)10 logging.info(f"DecisionTreeClassifier 准确率:{accuracy_score(y_test, y_pred)}")在上述代码中,掌柜还特意加入了sklearn中的决策树来进行对比。待上述代码运行结束后便可得到如下所示结果:
xxxxxxxxxx21- INFO: DecisionTree 准确率:0.97534155281572812- INFO: DecisionTreeClassifier 准确率:0.975674775074975从上述结果可以看出,两者在准确率上仅仅只有微小的差别。
3 决策树剪枝
在介绍完ID3和C4.5的决策树算法实现过程后,下面我们再来看最后一部分内容,那就是ID3和C4.5的剪枝过程。
3.1 剪枝原理
根据文章第8章 决策树与集成学习第8.4节内容可知,ID3和C4.5决策树的剪枝过程是通过最小化决策树整体的损失函数或者代价函数来实现。设树
其中经验熵为
进一步有
此时损失函数可以写为
其中
具体地,决策树的剪枝过程可以总结成如下步骤:
输入:生成算法产生的整个树
输出:修剪后的子树
(1) 计算每个叶节点的经验(信息)熵;
(2) 递归地从树的叶节点往上回溯;设一组叶节点回溯到其父节点之前与之后的整体树分别为
(3) 返回(2),直到不能继续为止,得到损失函数最小的子树
在正式实现剪枝部分的代码前,掌柜先来通过一个计算示例带着大家回顾一下剪枝地过程, 详细内容也可以参见文章决策树与集成学习第8.4节内容)。
3.2 剪枝示例
如图3所示,在考虑是否要减掉“学历等级”这个节点时,首先需要计算的就是剪枝前的损失函数数值
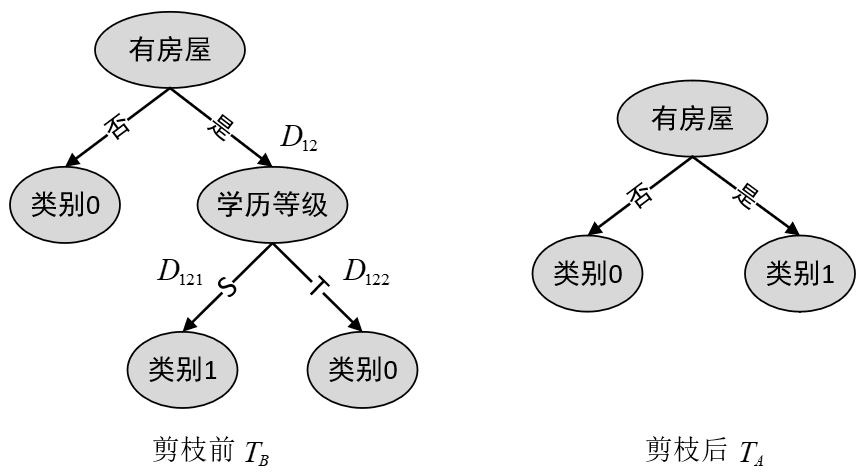
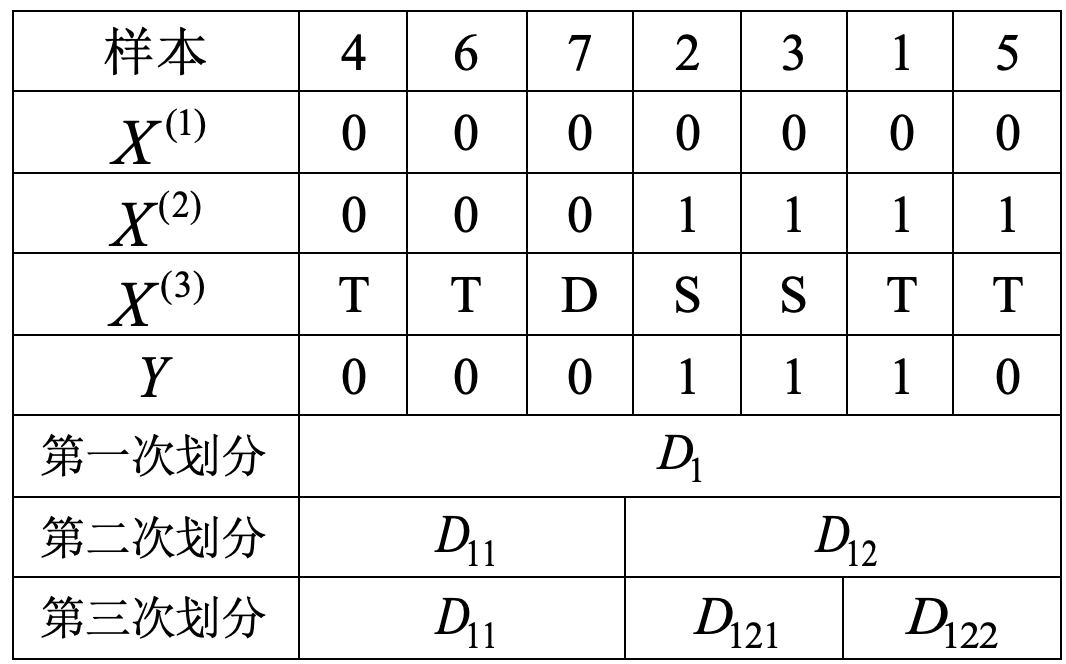
根据表2可知,“学历等级”这个节点对应的训练数据如表2所示(
根据式
进一步,根据式
同理可得,剪枝完成后树
由
3.3 剪枝判断实现
根据上述过程可知,在是否要进行剪枝之前需要计算剪枝前和剪枝后对应节点的损失值,然后再判断是否进行剪枝。因此,根据式
xxxxxxxxxx91def _compute_cost_in_leaf(labels):2 y_count = np.bincount(labels)3 n_samples = len(labels)4 cost = 05 for i in range(len(y_count)):6 if y_count[i] == 0:7 continue8 cost += y_count[i] * np.log2(y_count[i] / n_samples)9 return -cost在上述代码中,第2行是计算得到当前节点中的样本类别数,即每个类别有多少个样本;第3行是计算当前节点一共有多少样本;第5-8行是计算整个节点内部的损失值。
所有示例代码均可从此仓库获取:https://github.com/moon-hotel/MachineLearningWithMe
例如对于某个节点来说,其样本标签为[1,1,1,0],那么其对应的损失为:
xxxxxxxxxx21y_labels = np.array([1, 1, 1, 0])2_compute_cost_in_leaf(y_labels) # 3.24511进一步,我们再来实现对于决策树剪枝之前和剪枝之后的损失比较,实现代码如下:
xxxxxxxxxx111 def _is_pruning_leaf(self, node):2 if len(node.children) < 1: 3 node.leaf_costs = _compute_cost_in_leaf(self._y[node.sample_index])4 return False5 parent_cost = _compute_cost_in_leaf(self._y[node.sample_index]) # 剪枝后的损失6 for (_, leaf_node) in node.children.items(): # 剪枝前累加所有叶子节点的损失7 node.leaf_costs += leaf_node.leaf_costs8 if node.leaf_costs + self.alpha * node.n_leaf > parent_cost + self.alpha:9 # 当剪枝前的损失 > 剪枝后的损失, 则表示当前节点可以进行剪枝(减掉其所有孩子)10 return True11 return False在上述代码中,第2-4行是在当前节点为叶子节点时,计算叶子节点对应的损失;第5行是计算当前点中所有样本的损失,也就是剪枝后的损失值;第6-7行是计算以当前节点为根节点其所有叶子节点的损失和,也就是剪枝前的损失值;第8-11行是判断是否满足剪枝条件,并返回相应的结果。
例如对于表2中"学历等级"这个节点来说,其剪枝前和剪枝后的损失为:
xxxxxxxxxx111if __name__ == '__main__':2 x, y = load_simple_data()3 dt = DecisionTree(criterion='id3')4 dt.fit(x, y)5 nodes = dt.level_order(return_node=True)6# - DEBUG: 正在进行剪枝操作……7# - DEBUG: 当前节点的损失为:3.2451124978365313 + 0.08# - DEBUG: 当前节点的孩子节点损失和为:2.0 + 0.0 * 29# - DEBUG: 当前节点的损失为:6.896596952239761 + 0.010# - DEBUG: 当前节点的孩子节点损失和为:2.0 + 0.0 * 311# - DEBUG: 当前节点的损失为:4.348515545596771 + 0.0在上述结果中,第7-8行的输出便是对应式
3.3 剪枝过程实现
在实现完剪枝判断过程后,便可以依次遍历层次遍历的结果然后来判断是否对当前节点进行剪枝,而剪枝的做法也很简单直接将该节点children设置为空即可。整体实现代码如下所示:
xxxxxxxxxx141 def _pruning_leaf(self):2 level_order_nodes = self.level_order(return_node=True)3 for i in range(len(level_order_nodes) - 1, -1, -1):4 current_level_nodes = level_order_nodes[i] 5 for j in range(len(current_level_nodes)):6 current_node = current_level_nodes[j]7 if len(current_node.children) == 0:8 current_node.n_leaf = 19 else:10 for _, leaf_node in current_node.children.items():11 current_node.n_leaf += leaf_node.n_leaf 12 if self._is_pruning_leaf(current_node):13 current_node.children = {}14 current_node.n_leaf = 1在上述代码中,第2行是得到决策树的层次遍历结果;第3行是从下往上依次遍历每一层节点;第4行是取第i层的所有节点;第5-6行是开始遍历当前层中的每一个节点;第7-11行是用来累计以当前节点为根节点时其叶子节点的个数;第12-14行是判断是否需要剪枝操作。
3.4 使用示例
在实现完剪枝过程后,我们再来以3.2节中的例子进行示例。对于样本['0','1','S']和['0','1','T']来说,根据图1可知其分别属于1和0这两个类别;而如果对“学历等级”这个极点进行剪枝操作,那么这两个样本的预测类别都将是1这个类别。整个实现过程如下所示:
xxxxxxxxxx131def test_decision_tree_pruning():2 x, y = load_simple_data()3 dt = DecisionTree(criterion='id3', alpha=0.)4 dt.fit(x, y)5 x_test = np.array([['0', '1', 'S'],6 ['0', '1', 'T']])7 logging.debug(f"剪枝前的层次遍历结果")8 logging.info(f"剪枝前的预测类别:{dt.predict(x_test)}")9
10 dt = DecisionTree(criterion='id3', alpha=1.25)11 dt.fit(x, y)12 logging.debug(f"剪枝后的层次遍历结果")13 logging.info(f"剪枝后的预测类别:{dt.predict(x_test)}")上述代码运行结束后的结果如下所示:
xxxxxxxxxx21INFO: 剪枝前的预测类别:[1 0]2INFO: 剪枝后的预测类别:[1 1]4 总结
在这篇文章中,掌柜首先介绍了节点的定义以及回顾了ID3和C4.5决策树生成的原理;然后详细地分别介绍了信息熵与条件熵的实现、特征划分标准的实现、决策树的构建以及样本预测等;最后,一步一步介绍了决策树剪枝过程的代码实现,并通过具体的示例进行详细地解释。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎点赞分享!若有任何疑问与建议,请添加掌柜微信nulls8(备注来源)或文末留言进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1] https://scikit-learn.org/stable/modules/naive_bayes.html#naive-bayes
[2] 决策树与集成学习
[3] 示例代码:https://github.com/moon-hotel/MachineLearningWithMe
推荐阅读
[2] 第2章 从零认识线性回归(附高清PDF与教学PPT)
[3] 第3章 从零认识逻辑回归(附高清PDF与教学PPT)
[4] 第4章 模型的改善与泛化(附高清PDF与教学PPT)
[7] 第7章 文本特征提取与模型复用(附高清PDF与教学PPT)


